
爬虫
查看响应内容
response.status_code 查看状态码
response.encoding 查看编码
response.headers 查看请求头
response.text 实体
自动检测编码格式
import chardet
chardet.detect(response.content)
response.encoding = chardet.detect(response.content)['encoding'] # 设置编码方式
bs4
soup=BeautifulSoup(url,"lxml")
print(soup)
print(soup.div)
find("tagName") 等同于soup.div
print(soup.find('a'))
print(soup.find("div",class_='tab-item'))
soup.find(id="specific_id")
print(soup.find_all("a")) # 返回一个列表
print(soup.select(".info")) # 返回一个列表
print(soup.select(".tab-bar > .tab-item")[0]) 层级选择 >表示的一个层级,空格表示的多个层级
获取属性和标签之间的文本数据
print(soup.div.text/get_text()) # 获得文本
print(soup.select(".tab-bar > .tab-item")[0].get_text())
text/get_text() 可以获取某一个标签中所有的文本内容 string 只可以获取直系的文本内容
print(soup.a.string) # 直系的内容
获取属性值的内容
print(soup.a["href"])
.get_text() 和 .text将会输出div标签内的所有文本
.string 在尝试用于<div>标签时会返回None,因为<div>标签内有多个子节点。但是,当它用于<b>标签时,就能够返回"World",因为<b>标签内只有文本内容
.get_text(separator=" / ", strip=True) 以/为分隔符 排除空格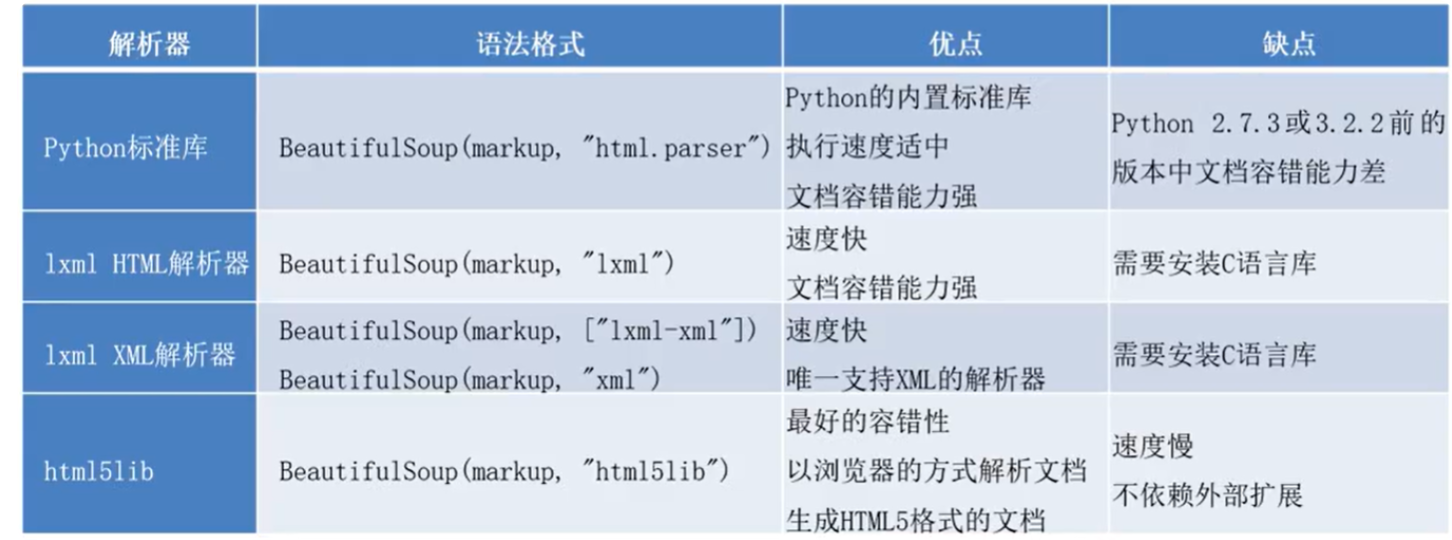


练习
import requests
from bs4 import BeautifulSoup
def xunhuan(i):
url = f"https://gz.lianjia.com/ershoufang/pg{i+1}/"
headers={
"User-Agent":"Mozilla/5.0 (X11; Linux x86_64; rv:91.0) Gecko/20100101 Firefox/91.0"
}
respondtext = requests.get(url,headers).text
soup = BeautifulSoup(respondtext,'lxml')
content = soup.select('html>body>div#content.content>div.leftContent>ul.sellListContent>li.clear.LOGCLICKDATA>div.info.clear>div.title>a')
for link in content:
href = link.get('href')
print(href)
print("===========")
for i in range(5):
xunhuan(i)xpath
xpath解析:
xpath解析原理
1.实例化一个etree的对象,且需要将被解析的页面源码数据加载到该对象中
2.调用etree对象中的xpath方法结合着xpath表达式实现标签的定位和内容的捕获、
# 如何实例化一个etree对象
from lxml import etree
1.将本地html文档加载到etree对象中
etree.parse(firePath)
2.互联网上的
etree.HTML("page_text")
'''
from lxml import etree
if __name__ == "__main__":
tree = etree.parse("F:\\HBuilderProjects\\page1\\123.html")
# r=tree.xpath("/html/head/title") # /单个层级
# r = tree.xpath("/html//title") # //多个层级
r = tree.xpath("//div") # //从任意部分开始定位
# 属性定位
r = tree.xpath('//div[@class="song"]')
# 索引定位
r = tree.xpath('//div[@class="song"]/p[3]') # 索引不是从0开始的
# 取文本
r = tree.xpath('//div[@class="tang"]//li[5]/a/text()')[0]
# /text() 获取的是标签中直系的文本内容
# //text() 获取标签中非直系的文本内容(下所有的文本内容)
# 取属性
r = tree.xpath('//div[@class="song"]//img/@src')
print(r)语法
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取(取子节点)。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置(取子孙节点)。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore | 选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
谓语
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()❤️] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang='eng'] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]//title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
选取未知节点
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
练习
import requests
import os
from lxml import etree
if __name__ == "__main__":
url = "https://pic.netbian.com/4kmeinv/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0"
}
response = requests.get(url=url,headers=headers)
# response.encoding='utf-8' 手动加编码不能解决
page_text = response.text
# 数据解析
tree = etree.HTML(page_text)
li_list = tree.xpath('//div[@class="slist"]//li')
if not os.path.exists('./piclibs'):
os.mkdir('./piclibs')
for li in li_list:
img_src = "https://pic.netbian.com"+li.xpath('./a/img/@src')[0]
print(img_src)
img_name = li.xpath('./a/img/@alt')[0]+'.jpg'
img_name = img_name.encode('iso-8859-1').decode('gbk')
# print(img_name,img_src)
# 请求图片
img_data = requests.get(url=img_src,headers=headers).content
img_path = 'piclibs/'+img_name
with open(img_path,'wb') as fp:
fp.write(img_data)
print(img_name,"下载成功!!!")
import requests
from bs4 import BeautifulSoup
import chardet
if __name__ == "__main__":
url = "https://www.shicimingju.com/book/sanguoyanyi.html"
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0"
}
page_text = requests.get(url=url,headers=headers).content
encoding = chardet.detect(page_text)["encoding"]
page_text = page_text.decode(encoding)
# 实例化对象
soup = BeautifulSoup(page_text,"lxml")
li_list = soup.select(".book-mulu > ul > li")
print(li_list)
fp = open("./sanguo.txt","w",encoding="utf-8")
for li in li_list:
title = li.a.string
detail_url = "https://www.shicimingju.com/"+li.a["href"]
# 对详情页发起请求,解析出章节内容
detail_page_text = requests.get(url=detail_url,headers=headers).content
# 自动检测编码
encoding = chardet.detect(detail_page_text)["encoding"]
# 根据检测到的编码进行解码
detail_page_text = detail_page_text.decode(encoding)
# 解析详情页
detail_soup = BeautifulSoup(detail_page_text,"lxml")
div_tag = detail_soup.find("div",class_='chapter_content')
# 解析到的内容
content = div_tag.text
fp.write(title+':'+content+'\n')
print(title,"爬取成功!!!")
import requests
import os
from lxml import etree
if __name__ == "__main__":
url = "https://pic.netbian.com/4kmeinv/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0"
}
response = requests.get(url=url,headers=headers)
# response.encoding='utf-8' 手动加编码不能解决
page_text = response.text
# 数据解析
tree = etree.HTML(page_text)
li_list = tree.xpath('//div[@class="slist"]//li')
if not os.path.exists('./piclibs'):
os.mkdir('./piclibs')
for li in li_list:
img_src = "https://pic.netbian.com"+li.xpath('./a/img/@src')[0]
print(img_src)
img_name = li.xpath('./a/img/@alt')[0]+'.jpg'
img_name = img_name.encode('iso-8859-1').decode('gbk')
# print(img_name,img_src)
# 请求图片
img_data = requests.get(url=img_src,headers=headers).content
img_path = 'piclibs/'+img_name
with open(img_path,'wb') as fp:
fp.write(img_data)
print(img_name,"下载成功!!!")
import requests
from lxml import etree
import os
if __name__ == "__main__":
url = "https://sc.chinaz.com/jianli/biaoge.html"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0"
}
response = requests.get(url=url, headers=headers)
response.encoding = 'utf-8'
page_text = response.text
tree = etree.HTML(page_text)
href_list = tree.xpath('/html/body/div[4]/div[2]/div/div/div')
if not os.path.exists('./jl'):
os.mkdir('./jl')
for href in href_list:
jl_href = href.xpath('./a/@href')[0]
jl_name = href.xpath('./a/img/@alt')[0]+'.rar'
down_text = requests.get(url=jl_href,headers=headers).text
tree = etree.HTML(down_text)
end_down_url_list = tree.xpath('//*[@id="saleinfo"]/div/a/@href')[0]
jl_data=requests.get(url=end_down_url_list,headers=headers).content
jl_path = './jl/'+jl_name
with open(jl_path,'wb') as fp:
fp.write(jl_data)
print(jl_name,"下载成功!!!")作业
作业一:腾讯课堂bs4
import requests
from bs4 import BeautifulSoup
import pandas as pd
data_list = []
def circle(i):
global data_list
n=0
url = f"https://ke.qq.com/course/list?mt=1001&quicklink=1&page={i+1}"
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0"
}
response = requests.get(url=url,headers=headers).text
soup = BeautifulSoup(response,"lxml")
url_list = soup.find("div",class_="course-list").find_all("a")
for url in url_list:
url = "https://ke.qq.com"+url["href"]
response = requests.get(url=url, headers=headers).text
soup = BeautifulSoup(response, "lxml")
# 1课程名
name = soup.find("div", class_="course-info").find("h3", class_="course-title").string
# 2价格
price = soup.find("div", class_="course-info").find("span", class_="course-price").string
# 3人数
peo_num = soup.find("div", class_="course-info").find("span", class_="course-nums").find("span").string
# 4涉及到的知识
incl_know = soup.find("div", class_="course-info").find("ul", class_="course-labels")
if incl_know:
incl_know = incl_know.find_all("a")
inc_know_list = []
for j in incl_know:
inc_know_list.append(j.string)
inc_know = ",".join(inc_know_list)
else:
inc_know = " "
# 5讲师名
try:
tech_name = soup.find("div", class_="teacher-intro-container").find("span",class_="kc-teacher-name kc-teacher-name-ellipsis").string
except AttributeError:
tech_name = "Unknown"
# 6机构名
sch_name = soup.find("div", class_="teacher-intro-container").find("p", class_="kc-teacher-summary").string
# 7好评度
rat = soup.find("aside", class_="aside").find("ul", class_="agency-hints").find_all("li")[0].find("span").string
# 8机构课程数
cource_num = soup.find("aside", class_="aside").find("ul", class_="agency-hints").find_all("li")[1].find("span").string
# 9机构学生数
sch_stu_num = soup.find("aside", class_="aside").find("ul", class_="agency-hints").find_all("li")[2].find("span").string
# 10网站url
stu_url = url
data_list.append([name,price,peo_num,inc_know,tech_name,sch_name,rat,cource_num,sch_stu_num,stu_url])
n +=1
print(f"第 {i + 1} 页的第 {n} 个课程已完成爬取")
for i in range(34):
circle(i)
df = pd.DataFrame(data_list, columns=['课程名字', '价格', '学习人数', '包含的知识', '教师名', '机构名', '评分', '课程数', '学生数','网站url'])
df.to_excel('腾讯课堂.xlsx', index=False)作业二:番茄小说bs4
import requests
from bs4 import BeautifulSoup
def xunhuan(i):
url = "https://fanqienovel.com/page/7143038691944959011?enter_from=stack-room"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
response = requests.get(url=url, headers=headers).text
soup = BeautifulSoup(response, "lxml")
# 1小说名
name = soup.select(".muye-page .info .info-name")[0].text
# 2状态
state = soup.select(".muye-page .info .info-label .info-label-yellow")[0].text
# 3类型
type = soup.select(".muye-page .info .info-label .info-label-grey")
type_list = []
for i in type:
type_list.append(i.text)
type_str = ",".join(type_list)
# 4字数
word_cnt = soup.select(".muye-page .info .info-count .info-count-word .detail")[0].text
unit_1 = soup.select(".muye-page .info .info-count .info-count-word .text")[0].text
word_cnt = word_cnt + unit_1
# 5观看人数
people_num = soup.select(".muye-page .info .info-count .info-count-read .detail")[0].text
unit_2 = soup.select(".muye-page .info .info-count .info-count-read .text")[0].text
people_num = people_num + unit_2
# 6最近更新章节
latestChapterUpdate = soup.select(".muye-page .info .info-last .info-last-title")[0].text
# 7最近更新时间
latestupdatetime = soup.select(".muye-page .info .info-last .info-last-time")[0].text
# 8作者名
author = soup.select(".muye-page .author .author-info .author-name-text")[0].text
# 9作者简介
author_intro = soup.select(".muye-page .author .author-info .author-desc")[0].text.replace("\n", '')
# 10作品简介
opus_intro = soup.select(".muye-page .page-body-wrap .page-abstract-content")[0].text.replace("\n", '')
print(name)
for i in range(2):
xunhuan(i)作业三:慕课bs4
import requests
from bs4 import BeautifulSoup
import pandas as pd
data_list = []
sum=0
def xunhuan(i):
global data_list
global sum
n=0
url = f"https://www.imooc.com/course/list?page={i+1}"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
reponse = requests.get(url=url, headers=headers).text
soup = BeautifulSoup(reponse, "lxml")
a_tags = soup.find("div", class_="course-list").find("div", class_="list max-1152 clearfix").find_all("a")
for a_tag in a_tags:
url = "https:" + a_tag["href"]
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
response = requests.get(url=url, headers=header).text
soup = BeautifulSoup(response, "lxml")
# 1课程名字
name = soup.find("div", class_="course-infos").find("h2", class_="l").string
# 2课程老师
teacher_info = soup.find("div", class_="teacher-info l").find("span", class_="tit").find("a").string
# 3老师职位
teacher_posi = soup.find("div", class_="teacher-info l").find("span", class_="job").string
# 4难度
difficulty = soup.find("div", class_="static-item l").find("span", class_="meta-value").string
# 5时长
time = soup.select("#main > div.course-infos > div.w.pr > div.statics.clearfix > div:nth-child(3) > span.meta-value")[0].string
# 6评分
score = soup.find("div", class_="static-item l score-btn").find("span", class_="meta-value").string
# 7评价人数
review_num = soup.find("span", class_="person-num l").string
# 8课程须知
notice = soup.find("dd", class_="autowrap")
if notice:
notice = notice.string
else:
notice = "值为空"
# 9简介
intro = soup.find("div", class_="course-description course-wrap").string
data_list.append([name, teacher_info, teacher_posi, difficulty, time, score, review_num, notice, intro])
n+=1
sum+=1
print("第", i + 1, "页的第",n,"个课程已完成爬取")
for i in range(14):
xunhuan(i)
print("第",i+1,"页已完成爬取")
print("=========================")
print("所有课程以爬取完成,共",sum,"个课程")
df = pd.DataFrame(data_list, columns=['课程名字', '课程老师', '老师职位', '难度', '时长', '评分', '评价人数', '课程须知', '简介'])
df.to_excel('kecheng.xlsx', index=False)作业四:电影xpath
import requests
from lxml import etree
import pandas as pd
data_list = []
def xunhuan(i):
global data_list
url = f"https://ssr1.scrape.center/page/{i+1}"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0"
}
response = requests.get(url=url,headers=headers).text
tree = etree.HTML(response)
bq_url = tree.xpath('//*[@id="index"]/div[1]/div[1]//div[@class="el-row"]/div[1]/a/@href')
for i in bq_url:
list_url = "https://ssr1.scrape.center"+i
response = requests.get(url=list_url, headers=headers).text
tree = etree.HTML(response)
# 1电影名
name = tree.xpath('//*[@id="detail"]/div[1]/div/div/div[1]/div/div[2]/a/h2/text()')[0]
# 2分类
fenlei = tree.xpath('//*[@id="detail"]/div[1]/div/div/div[1]/div/div[2]/div[1]/button/span/text()')
fenlei = ",".join(fenlei)
# 3地区
area = tree.xpath('//*[@id="detail"]/div[1]/div/div/div[1]/div/div[2]/div[2]/span[1]/text()')[0]
# 4上映时间
date_1 = tree.xpath('//*[@id="detail"]/div[1]/div/div/div[1]/div/div[2]/div[3]/span/text()')
if date_1:
# 如果列表不为空,取第一个元素
date = date_1[0]
else:
# 如果列表为空,设置默认值或进行其他处理
date = '日期未知' # 或者您可以选择其他合适的默认值或处理方式
# 5评分
pingen = tree.xpath('//*[@id="detail"]/div[1]/div/div/div[1]/div/div[3]/p[1]//text()')[0].strip()
# 6导演
daoyan = tree.xpath('//*[@id="detail"]/div[2]/div/div/div/div/div/p/text()')[0]
# 7演员
yanyuan = tree.xpath('//*[@id="detail"]/div[3]/div/div/div/div/div/p[1]/text()')
yanyuan = ",".join(yanyuan)
# 8剧中人物
renwu = tree.xpath('//*[@id="detail"]/div[3]/div/div/div/div/div/p[2]/text()')
renwu_list = []
for i in renwu:
renwu_list.append(i.split(":")[1])
renwu = ",".join(renwu_list)
# 9简介
jianjie = tree.xpath('//*[@id="detail"]/div[1]/div/div/div[1]/div/div[2]/div[4]/p/text()')[0].strip()
data_list.append([name, fenlei, area, date, pingen, daoyan, yanyuan, renwu, jianjie])
for i in range(50):
xunhuan(i)
print("第",i+1,"页已完成")
df = pd.DataFrame(data_list, columns=['电影名', '分类', '地区', '上映时间', '评分', '导演', '演员', '剧中人物', '简介'])
df.to_excel('movies.xlsx', index=False)作业五:学校课程bs4
import requests
from bs4 import BeautifulSoup
url = "https://www.ehuixue.cn/index/detail/index?cid=40444"
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0"
}
page_text = requests.get(url=url,headers=headers).text
soup = BeautifulSoup(page_text, "lxml")
# 课程
name = soup.find("div",class_="ctitle").string.strip()
# 教师
teacher_main = soup.find("table",class_="cdetail").find("tr").find_all("td")[1].get_text().strip().split("/")[0]
# 学校
school= soup.find("table",class_="cdetail").find("tr").find_all("td")[1].string.strip().split("/")[1]
# 人数
people_count = soup.find("table",class_="cdetail").find_all("tr")[1].find_all("td")[1].string.strip()
# 开课日期
date = soup.find("table",class_="cdetail").find_all("tr")[2].find_all("td")[1].string.strip().replace(" ", "").replace("\n", "")
# 教学进度
progress = soup.find("table",class_="cdetail").find_all("tr")[3].find_all("td")[1].find("div",class_="status-icon active").string.strip()
# 课程期次
duration = soup.find("table",class_="cdetail").find_all("tr")[4].find("li",class_="layui-nav-item").find("a").string.strip()
# 课程总共期次
duration1 = soup.find("table",class_="cdetail").find_all("tr")[4].find("span",class_="color1").string.strip().replace(" ","").replace("\n", "")
# 评分
score = soup.find("div",class_="layui-tab layui-tab-brief").find(id="cscore").string
# 评价条数
count = soup.find("div",class_="layui-tab layui-tab-brief").find(id="courseratenum").string
print(name)作业六:e会学 xpath bs4 post请求
import requests
from bs4 import BeautifulSoup
from lxml import etree
import pandas as pd
data=[]
def test(i):
# 请求的URL
url = 'https://www.ehuixue.cn/index/clist/view'
# 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0',
'X-Requested-With': 'XMLHttpRequest',
'Referer': 'https://www.ehuixue.cn/index/clist/index.html',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'text/html, */*; q=0.01',
# 可能需要其他 headers,例如 'Origin', 'Sec-Fetch-*' 等
}
# 请求的负载(数据)
post_data = {
'p': i+1,
'limit': 16,
'codeid': 0,
'type': 0,
'status': 0,
'sort': 0,
'orgid': '',
'level': 1
}
# 发送POST请求
response = requests.post(url, headers=headers, data=post_data).text
tree = etree.HTML(response)
url_list = tree.xpath('//li/a/@href')
for url in url_list:
url = "https://www.ehuixue.cn"+url
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0"
}
page_text = requests.get(url=url, headers=headers).text
soup = BeautifulSoup(page_text, "lxml")
base_select = ".container > .ctop > .cbox > table tr td"
name = soup.select(base_select+" .ctitle")[0].text.strip()
teacher = soup.select(base_select+" .cdetail tr:nth-child(1) > td")[1].text.strip().split('/')[0]
school =soup.select(base_select+" .cdetail tr:nth-child(1) > td")[1].text.strip().split('/')[1]
date = soup.select(base_select+" .cdetail tr:nth-child(3) > td")[1].get_text().strip().replace(" ", "").replace("\n", "")
progress = soup.select(base_select+" .cdetail tr:nth-child(4) .active")[0].text.strip()
duration = soup.select(base_select+" .cdetail tr:nth-child(5) a")[0].text.strip()
duration1 = soup.select(base_select+" .cdetail tr:nth-child(5) td:nth-of-type(3)")[0].text.strip().replace(" ", "").replace("\n", "")
score = soup.select(".container > .ctop + div .layui-tab-content table tr:nth-child(1) .cscore")[0].text
count = soup.select(".container > .ctop + div .layui-tab-content table tr:nth-child(1) #courseratenum")[0].text
# 创建一个字典,其中键是字段名,值是对应的数据
global data
data_dict = {
'name': name,
'teacher': teacher,
'school': school,
'date': date,
'progress': progress,
'duration': duration,
'duration1': duration1,
'score': score,
'count': count
}
data.append(data_dict)
for i in range(1):
test(i)
print("第", i+1, "页已完成爬取")
# 创建一个 DataFrame
df = pd.DataFrame(data)
# 将 DataFrame 保存为 Excel 文件
df.to_excel('output.xlsx', index=False)
====================================================================
import requests
from bs4 import BeautifulSoup
from lxml import etree
import pandas as pd
data=[]
def test(i):
# 请求的URL
url = 'https://www.ehuixue.cn/index/clist/view'
# 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0',
'X-Requested-With': 'XMLHttpRequest',
'Referer': 'https://www.ehuixue.cn/index/clist/index.html',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'text/html, */*; q=0.01',
# 可能需要其他 headers,例如 'Origin', 'Sec-Fetch-*' 等
}
# 请求的负载(数据)
post_data = {
'p': i+1,
'limit': 16,
'codeid': 0,
'type': 0,
'status': 0,
'sort': 0,
'orgid': '',
'level': 1
}
# 发送POST请求
response = requests.post(url, headers=headers, data=post_data).text
tree = etree.HTML(response)
url_list = tree.xpath('//li/a/@href')
for url in url_list:
url = "https://www.ehuixue.cn"+url
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0"
}
page_text = requests.get(url=url, headers=headers).text
soup = BeautifulSoup(page_text, "lxml")
name = soup.select(".container > .ctop > .cbox > table tr td .ctitle")[0].text.strip()
teacher_main = soup.select(".container > .ctop > .cbox > table tr td .cdetail tr:nth-child(1) > td")[1].text.strip().split('/')[0]
school =soup.select(".container > .ctop > .cbox > table tr td .cdetail tr:nth-child(1) > td")[1].text.strip().split('/')[1]
date = soup.select(".container > .ctop > .cbox > table tr td .cdetail tr:nth-child(3) > td")[1].get_text().strip().replace(" ", "").replace("\n", "")
progress = soup.select(".container > .ctop > .cbox > table tr td .cdetail tr:nth-child(4) .active")[0].text.strip()
duration = soup.select(".container > .ctop > .cbox > table tr td .cdetail tr:nth-child(5) a")[0].text.strip()
duration1 = soup.select(".container > .ctop > .cbox > table tr td .cdetail tr:nth-child(5) td:nth-of-type(3)")[0].text.strip().replace(" ", "").replace("\n", "")
score = soup.select(".container > .ctop + div .layui-tab-content table tr:nth-child(1) .cscore")[0].text
count = soup.select(".container > .ctop + div .layui-tab-content table tr:nth-child(1) #courseratenum")[0].text
teacher = soup.select(".container > .ctop + div .cteachertab a")[0].text.strip()
people_count = soup.select(".container > .ctop > .cbox > table tr td .cdetail tr:nth-child(2) > td:nth-child(2)")[0].text.strip()
# 创建一个字典,其中键是字段名,值是对应的数据
global data
data_dict = {
'课程名称': name,
'主讲教师': teacher_main,
'观看人数':people_count,
'学校': school,
'开课周期': date,
'教学进度': progress,
'课程期次': duration,
'课程期次状态': duration1,
'教师': teacher,
'评分': score,
'评论条数': count
}
data.append(data_dict)
for i in range(35):
test(i)
print("第", i+1, "页已完成爬取")
# 创建一个 DataFrame
df = pd.DataFrame(data)
# 将 DataFrame 保存为 Excel 文件
df.to_excel('output.xlsx', index=False)
import requests
from bs4 import BeautifulSoup
from lxml import etree
import pandas as pd
data=[]
sum = 0
def circulate(i):
n = 0
# 请求的URL
url = 'https://www.ehuixue.cn/index/clist/view'
# 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0',
'X-Requested-With': 'XMLHttpRequest',
'Referer': 'https://www.ehuixue.cn/index/clist/index.html',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'text/html, */*; q=0.01',
}
# 请求的负载(数据)
post_data = {
'p': i+1,
'limit': 16,
'codeid': 0,
'type': 0,
'status': 0,
'sort': 0,
'orgid': '',
'level': 1
}
# 发送POST请求
response = requests.post(url, headers=headers, data=post_data).text
tree = etree.HTML(response)
url_list = tree.xpath('//li/a/@href')
for url in url_list:
url = "https://www.ehuixue.cn"+url
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0"
}
page_text = requests.get(url=url, headers=headers).text
soup = BeautifulSoup(page_text, "lxml")
# 课程
name = soup.find("div", class_="ctitle").string.strip()
# 教师
teacher_main = soup.find("table", class_="cdetail").find("tr").find_all("td")[1].get_text().strip().split("/")[0]
# 学校
school = soup.find("table", class_="cdetail").find("tr").find_all("td")[1].string.strip().split("/")[1]
# 人数
people_count = soup.find("table", class_="cdetail").find_all("tr")[1].find_all("td")[1].string.strip()
# 开课日期
date = soup.find("table", class_="cdetail").find_all("tr")[2].find_all("td")[1].string.strip().replace(" ","").replace("\n", "")
# 教学进度
progress = soup.find("table", class_="cdetail").find_all("tr")[3].find_all("td")[1].find("div",class_="status-icon active").string.strip()
# 课程期次
duration = soup.find("table", class_="cdetail").find_all("tr")[4].find("li", class_="layui-nav-item").find("a").string.strip()
# 课程总共期次
try:
duration1 = soup.find("table", class_="cdetail").find_all("tr")[4].find("span",class_="color1").string.strip().replace(" ", "").replace("\n", "")
except AttributeError:
duration1 = " "
# 评分
score = soup.find("div", class_="layui-tab layui-tab-brief").find(id="cscore").string
# 评价条数
count = soup.find("div", class_="layui-tab layui-tab-brief").find(id="courseratenum").string
global data
global sum
data.append([name, teacher_main, school, people_count, date, progress, duration, duration1, score,count])
n += 1
sum += 1
print("第", i + 1, "页的第", n, "个课程已完成爬取")
for i in range(35):
circulate(i)
print("第", i+1, "页已完成爬取")
df = pd.DataFrame(data, columns=['课程', '教师', '学校', '人数', '开课日期', '教学进度', '课程期次', '课程总共期次', '评分','评价条数'])
# 数据清洗
# 删除所有值均为 NaN 的行
df = df.dropna(how='all')
# 从字符串列中去除前导/尾随空格
df['课程'] = df['课程'].str.strip()
df['教师'] = df['教师'].str.strip()
df['学校'] = df['学校'].str.strip()
# 保存
df.to_excel('kecheng.xlsx', index=False)作业七:梨视频xpath
import requests
from lxml import etree
url = "https://www.pearvideo.com/category_1"
headers = {
"User":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0"
}
page_text = requests.get(url=url,headers=headers).text
tree = etree.HTML(page_text)
li_list = tree.xpath('//*[@id="listvideoListUl"]/li')
for li in li_list:
detail_url = 'https://www.pearvideo.com/'+li.xpath('./div/a/@href')[0]
name = li.xpath('./div/a/div[2]/text()')[0]+'.mp4'
detail_page_text = requests.get(url=detail_url,headers=headers).text
tree = etree.HTML(detail_page_text)
video_list = tree.xpath('//*[@id="poster"]/img/@src')
print(video_list)比赛
import requests
from bs4 import BeautifulSoup
from lxml import etree
import pandas as pd
# ['总价','户型','朝向','建筑面积','楼层','单价','装修']
list = []
def xunhuan(i):
global list
url = f"https://gz.lianjia.com/ershoufang/pg{i + 1}/"
headers = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:91.0) Gecko/20100101 Firefox/91.0"
}
respondtext = requests.get(url, headers).text
soup = BeautifulSoup(respondtext, 'lxml')
content = soup.select(
'html>body>div#content.content>div.leftContent>ul.sellListContent>li.clear.LOGCLICKDATA')
for link in content:
price = link.select("div.info.clear div.priceInfo div.totalPrice.totalPrice2 span")[0].string
huxing = link.select("div.info.clear div.address div.houseInfo")[0].get_text().split('|')[0]
chaoxiang = link.select("div.info.clear div.address div.houseInfo")[0].get_text().split('|')[2]
mianji = link.select("div.info.clear div.address div.houseInfo")[0].get_text().split('|')[1]
louceng = link.select("div.info.clear div.address div.houseInfo")[0].get_text().split('|')[4]
danjia = link.select("div.info.clear div.priceInfo div.unitPrice span")[0].string
zhuangxiu = link.select("div.info.clear div.address div.houseInfo")[0].get_text().split('|')[3]
list.append([price,huxing,chaoxiang,mianji,louceng,danjia,zhuangxiu])
for i in range(5):
xunhuan(i)
df = pd.DataFrame(list,columns=['总价','户型','朝向','建筑面积','楼层','单价','装修'])
df.to_excel("/data/result1_2.xlsx",index=False)正则表达式
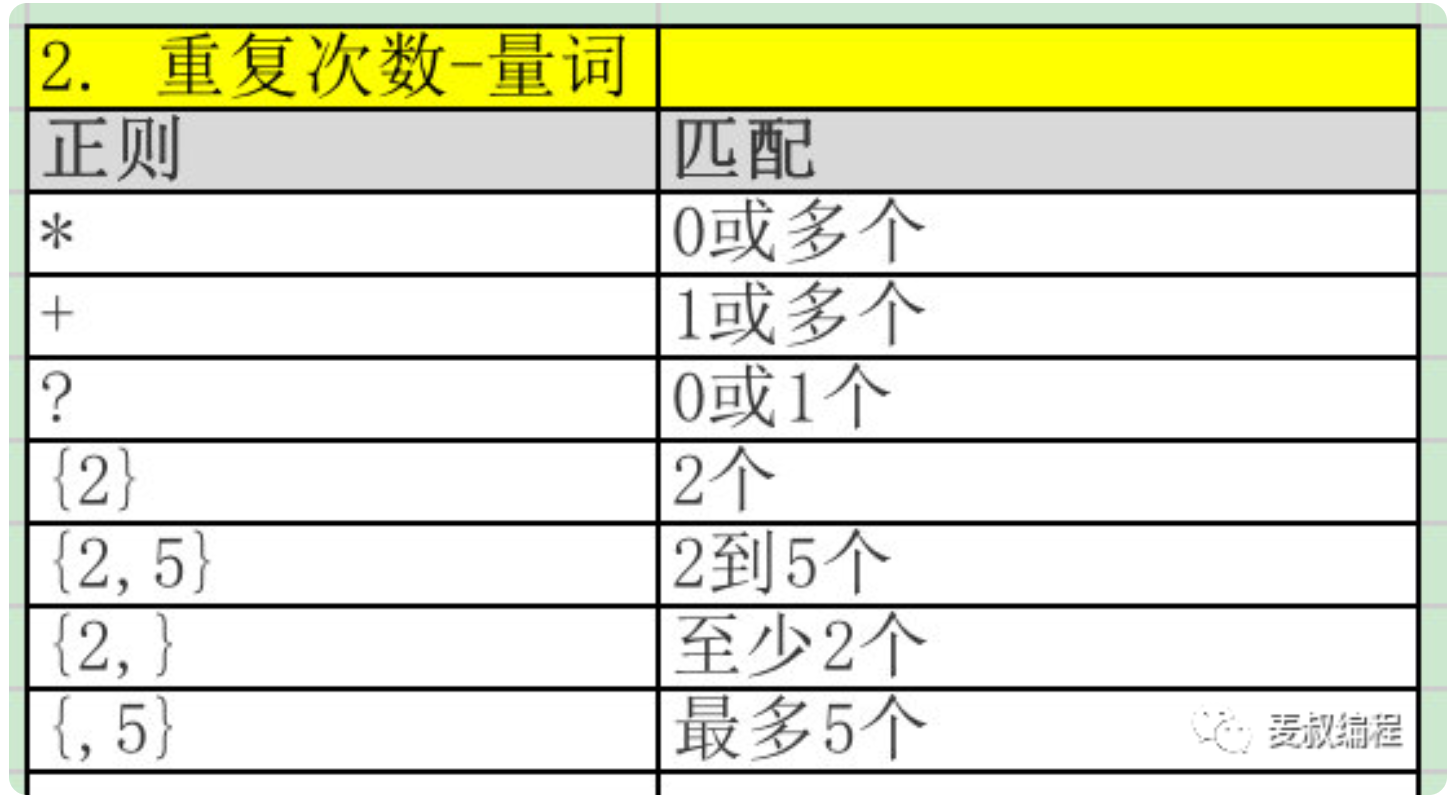
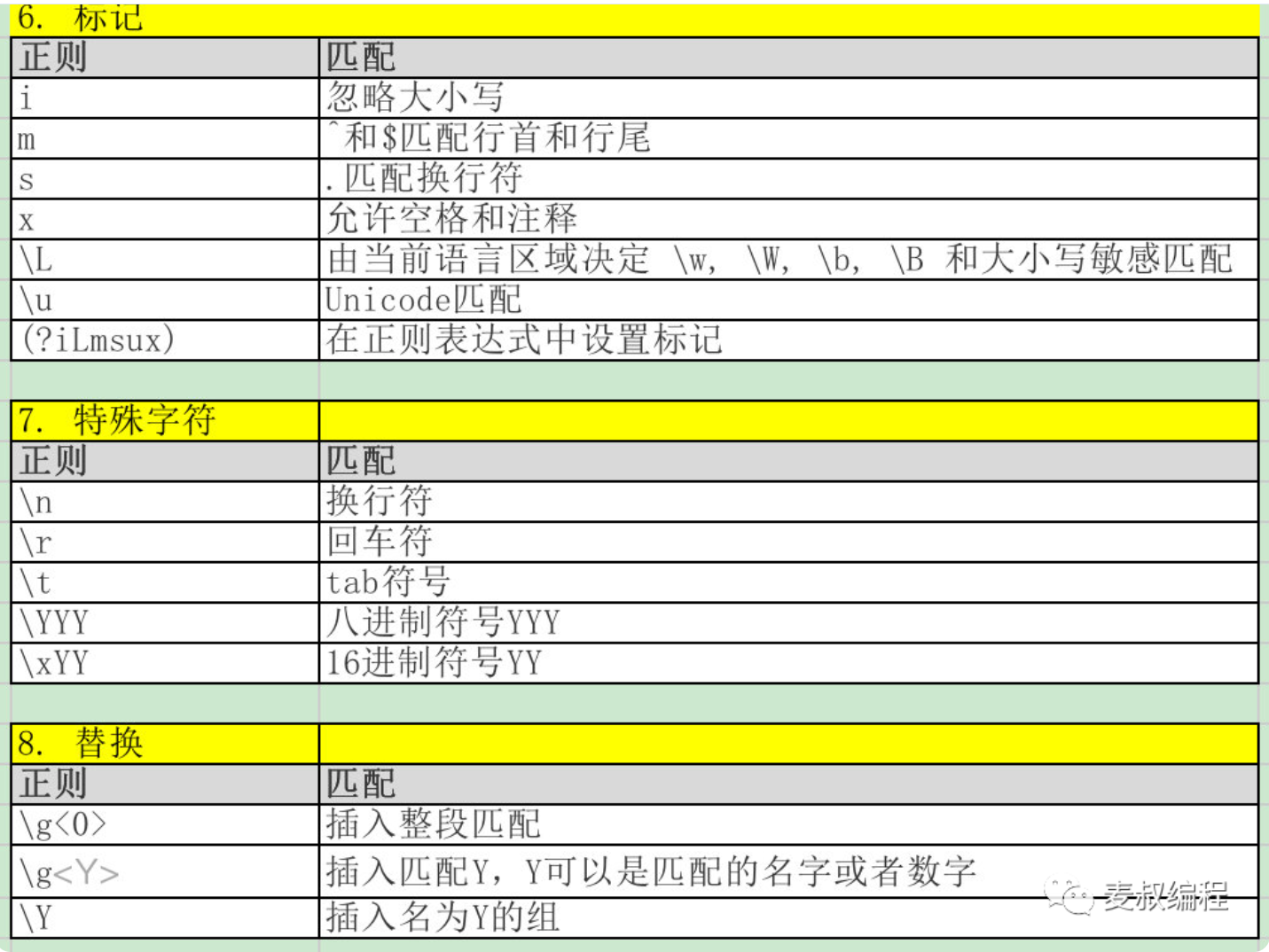
1. 正则表达式的7个境界
假设有一段文字:
text = '身高:178,体重:168,学号:123456,密码:9527'要确定文本中是否包含数字123456,我们可以用in运算符,也可以使用index函数:
text = '身高:178,体重:168,学号:123456,密码:9527'
target = '123456'
if target in text:
print('找到了')
print(text.index(target))下面我们通过8个例子,来熟悉正则表达式,后面再讲写正则表达式的套路和正则表达式的语法。
level1 - 固定的字符串
要求:确定字符串中是否有123456
import re
text = '麦叔身高:178,体重:168,学号:123456,密码:9527'
print(re.findall(r'123456', text))代码说明:
- 第1行,引入正则表达式模块re
- 第3行,使用re的findall()方法找到所有符合模式的字符串,这里的模式就是123456,也就是说找到字符串中所有的123456。
- findall()方法的第1个参数是模式,第2个参数是要查找的字符串。
- 模式中会有一些特殊字符,所以用r表示这是一个raw字符串,让Python不要去转义里面的特殊字符。
上面程序的运行结果是:[123456],因为整个字符串中就1个123456。
level1就是一个固定的字符串匹配,可以用传统的字符串匹配解决。
level2 - 某一类字符
要求:找出所有的单个的数字
text = '麦叔身高:178,体重:168,学号:123456,密码:9527'
print(re.findall(r'\d', text))这个表达式\d表示所有的数字,所以1,7,8,1,6,8等都可以匹配到。这是很简单的模式,只匹配1个单独的数字。
如果你完全没有接触过正则表达式,看着有点懵逼,去我看在B站的视频吧,让我手把手教你!
level3 - 重复某一类字符
要求:找所有的数字,比如178,168,123456,9527等。
text = '麦叔身高:178,体重:168,学号:123456,密码:9527'
print(re.findall(r'\d+', text))
+ 表示一个或者多个
? 表示0个或者1个
* 表示0个或者多个
r'\d[a-z]' [a-z] 表示范围 或者枚举
r'\d{3}' {3} 表示出现的次数 {1,3} 表示1-3这个模式\d+在\d的后面增加了+号,表示数字可以出现1到多次,所以178等都符合它的要求。
leve4 - 组合level2
要求:找出座机号码
text = '麦叔电话是18812345678,他还有一个电话号码是18887654321,他爱好的数字是01234567891,他的座机是:0571-52152166'
print(re.findall(r'\d{4}-\d{8}', text))\d{4}-\d{8}这是一个组合的模式,表示前面4个数字,中间一个横杠,后面8个数字。
这里会匹配一个结果:0571-52152166
leve5 - 多种情况
要求:找出手机号码或者座机号码
text = '麦叔电话是18812345678,他还有一个电话号码是18887654321,他爱好的数字是01234567891,他的座机是:0571-52152166'
print(re.findall(r'\d{4}-\d{8}|1\d{10}', text))比上面有复杂了点,因为使用竖线(|)来表示”或“的关系,就是手机号码和电话号码都可以。
这里会匹配三个结果:18812345678,18887654321,0571-52152166。
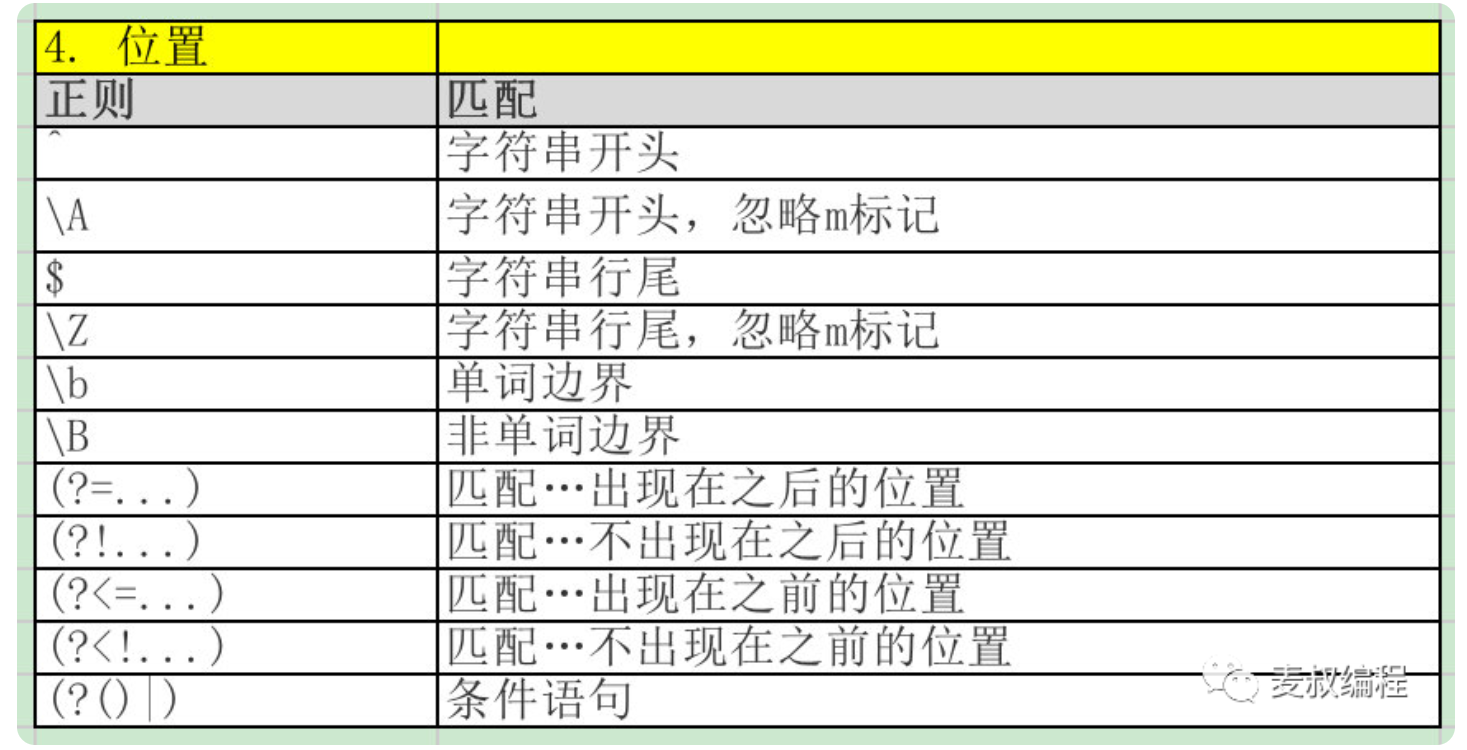
level6 - 限定位置
要求:在句子开头的手机号码,或座机
text = '18812345678,他还有一个电话号码是18887654321,他爱好的数字是01234567891,他的座机是:0571-52152166'
print(re.findall(r'^1\d{10}|^\d{4}-\d{8}', text))
$ 表示最后在表达式的最开始使用了^符号,表示一定要在句子的开头才行。这时候只有18812345678能匹配上。
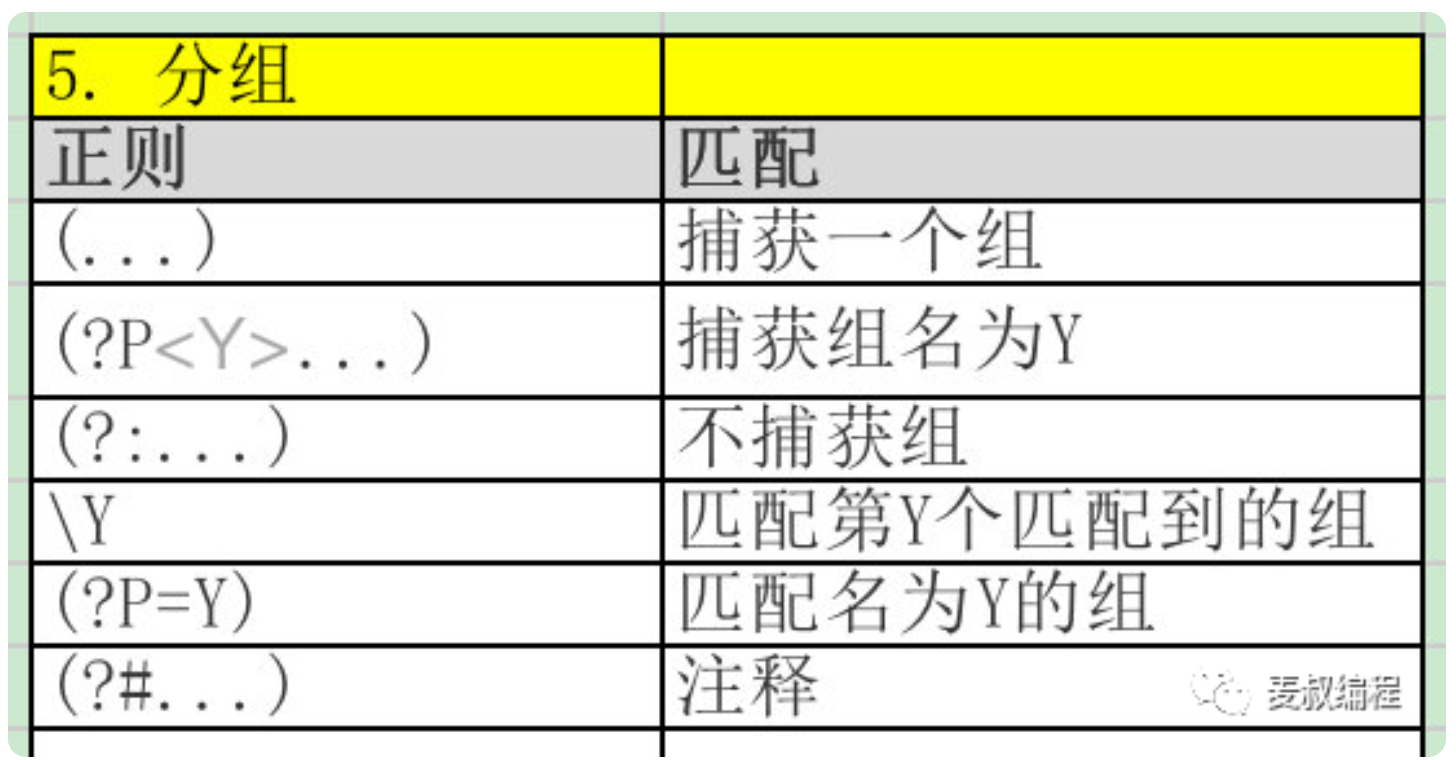
level7 - 内部约束
要求:找出形如barbar, dardar的前后三个字母重复的字符串
text = 'barbar carcar harhel'
print(re.findall(r'(\w{3})(\1)', text))这里barbar和carcar会匹配上,但harhel不会被匹配,因为它不是3个字符重复的。
\w{3}表示3个字符,放在小括号中(\w{3})就成为一个分组,而后面的(\1)表示它里面的内容和第1个括号里的内容必须相同,其中的1就表示第1个括号,也就是说3个字符要重复出现两次。
2. 写正则表达式的步骤
如何写正则表达式呢?我总结了几个步骤。不管多复杂,基本上都百试不爽。
我们仍然以包含分机号码的座机电话号码为例,比如0571-88776655-9527,演示下面的步骤:
确定模式包含几个子模式
它包含3个子模式:0571-88776655-9527。这3个子模式用固定字符连接。
各个部分的字符分类是什么
这3个子模式都是数字类型,可以用\d。现在可以写出模式为:
\d-\d-\d各个子模式如何重复
第1个子模式重复3到4次,因为有010和021等直辖市
第2个子模式重复7到8次,有的地区只有7位电话号码
第3个子模式重复3-4次
加上次数限制后,模式成为:
\d{3,4}-\d{7,8}-\d{3,4}但有的座机没有分机号,所以我们用或运算符让它支持两者:
\d{3,4}-\d{7,8}-\d{3,4}|\d{3,4}-\d{7,8}是否有外部位置限制
没有
是否有内部制约关系
没有
经过一通分析,最后的正则就写成了,测试一下:
text = '随机数字:01234567891,座机1:0571-52152166,座机2:0571-52152188-1234'
print(re.findall(r'\d{3,4}-\d{7,8}-\d{3,4}|\d{3,4}-\d{7,8}', text))最后的结果是:两个座机都可以找出来。
3. 语法规则
正则表达式几十个符号,看似很复杂,但如果能否分清楚类别和作用,就没那么复杂了。
- 字符类别表达 - 表达某一类字符,比如数字,字母,3到9之间的任何数字等

- 字符的重复次数,也叫做量词。比如身份证是数字重复15或18次,也就是:\d{15}或者\d{18}。
- 组合模式:把多个简单的模式组合在一起,可以是拼接,也可以是二者选其一。

- 位置:限定模式出现的位置,比如行首,行尾,或者在特定字符之后等。
import re
# 以"你好"开始的字符串
pattern1 = r'^你好'
text1 = '你好,今天天气不错'
result1 = re.match(pattern1, text1)
print("匹配结果1:", result1.group() if result1 else "无匹配")
# 以"再见"结束的字符串
pattern2 = r'再见$'
text2 = '我们现在说再见'
result2 = re.search(pattern2, text2)
print("匹配结果2:", result2.group() if result2 else "无匹配")
# 匹配包含完整单词"苹果"的字符串
pattern3 = r'\b苹果\b'
text3 = '我喜欢吃苹果'
result3 = re.search(pattern3, text3)
print("匹配结果3:", result3.group() if result3 else "无匹配")
# 匹配单词边界且紧跟着"苹果"的字符串
# 注意:Python 的 `re` 库中 `\b` 代表单词边界,`B` 字符在正则中不表示边界
pattern4 = r'\b苹果'
text4 = '这里有苹果'
result4 = re.search(pattern4, text4)
print("匹配结果4:", result4.group() if result4 else "无匹配")
# 匹配"颜色"后可选跟一个空格的字符串
pattern5 = r'颜色 ?'
text5 = '这件衣服的颜色 很好看'
result5 = re.search(pattern5, text5)
print("匹配结果5:", result5.group() if result5 else "无匹配")
# 确保"颜色"不是直接跟着"无"的字符串
pattern6 = r'颜色(?!无)'
text6 = '这件衣服的颜色很鲜艳'
result6 = re.search(pattern6, text6)
print("匹配结果6:", result6.group() if result6 else "无匹配")
# 确保字符串中的"颜色"之前是"明亮"
pattern7 = r'(?<=明亮)颜色'
text7 = '明亮颜色的衣服最吸引人'
result7 = re.search(pattern7, text7)
print("匹配结果7:", result7.group() if result7 else "无匹配")- 分组,把一个正则表达式分成几个部分,这样可以重复某个分组,或者指定两个分组必须相同等额外的要求。
其他
4. Python正则模块re的用法
python的re模块还比较简单,包括以下几个方法:
查找
- re.search():查找符合模式的字符,只返回第一个,返回Match对象
- re.match():和search一样,但要求必须从字符串开头匹配
- re.findall():返回所有匹配的字符串列表
- re.finditer():返回一个迭代器,其中包含所有的匹配,也就是Match对象
import re
text ="abc, Abc, ABC"
m= re.search(r'abc',text)
print(m.group())替换
- re.sub():替换匹配的字符串,返回替换完成的文本
- re.subn():替换匹配的字符串,返回替换完成的文本和替换的次数
分割
- re.split():用匹配表达式的字符串做分隔符分割原字符串
- re.compile():把正则表达式编译成一个对象,方便后面使用
re.search()
- 用法: re.search(pattern, string) 在字符串中搜索第一个与模式匹配的字符串。如果找到匹配项,则返回一个 Match 对象;否则返回 None。
- 实例:
import re
text = "Hello, world!"
match = re.search(r"world", text)
if match:
print(match.group()) # 输出: worldre.match()
- 用法: re.match(pattern, string) 从字符串的开头开始匹配模式。如果开头的字符与模式匹配,则返回一个 Match 对象;否则返回 None。
- 实例:
import re
text = "Hello, world!"
match = re.match(r"Hello", text)
if match:
print(match.group()) # 输出: Hellore.findall()
- 用法: re.findall(pattern, string) 返回字符串中所有与模式匹配的非重叠字符串的列表。
- 实例:
import re
text = "The number 15 and 42 are here"
numbers = re.findall(r"\d+", text)
print(numbers) # 输出: ['15', '42']re.finditer()
- 用法: re.finditer(pattern, string) 返回一个迭代器,包含字符串中所有与模式匹配的非重叠匹配项(Match 对象)。
- 实例:
import re
text = "The number 15 and 42 are here"
for match in re.finditer(r"\d+", text):
print(match.group()) # 输出: 15, 42re.sub()
- 用法: re.sub(pattern, repl, string) 在字符串中找到与模式匹配的所有子串,并将其替换为 repl。
- 实例:
import re
text = "Hello, world!"
replaced_text = re.sub(r"world", "Python", text)
print(replaced_text) # 输出: Hello, Python!re.subn()
- 用法: re.subn(pattern, repl, string) 类似于 re.sub,但返回一个包含新字符串和替换次数的元组。
- 实例:
import re
text = "Hello, world! world!"
replaced_text, count = re.subn(r"world", "Python", text)
print(replaced_text) # 输出: Hello, Python! Python!
print(count) # 输出: 2re.split()
- 用法: re.split(pattern, string) 使用模式匹配的字符串分割原字符串。
- 实例:
import re
text = "one, two, three"
words = re.split(r",\s*", text)
print(words) # 输出: ['one', 'two', 'three']re.compile()
- 用法: re.compile(pattern) 将正则表达式模式编译成一个正则表达式对象,该对象可以用于 match、search 等方法。
- 实例:
import re
pattern = re.compile(r"\d+")
text = "12 drummers drumming, 11 pipers piping, 10 lords a-leaping"
numbers = pattern.findall(text)
print(numbers) # 输出: ['12', '11', '10']在Python的正则表达式中,group() 和 groups() 方法用于从匹配的字符串中提取特定部分。它们是 re.Match 对象的方法,这个对象是通过 re.search(), re.match(), re.findall() 等函数执行正则表达式操作后返回的。
group()
- group() 方法用于获取正则表达式匹配的特定部分。
- 如果正则表达式中有括号(也就是分组),group() 可以获取这些分组匹配的文本。
- group(0) 或 group() 返回整个匹配的字符串,group(1) 返回第一个分组匹配的文本,group(2) 返回第二个分组匹配的文本,依此类推。
- 如果正则表达式中没有分组,则 group() 将返回整个匹配的字符串。
例如:
import re
pattern = re.compile(r'(\d{3})-(\d{2})-(\d{4})')
match = pattern.search('我的电话号码是 123-45-6789。')
print(match.group()) # 输出整个匹配的字符串 '123-45-6789'
print(match.group(0)) # 同样输出整个匹配的字符串 '123-45-6789'
print(match.group(1)) # 输出第一个分组匹配的字符串 '123'
print(match.group(2)) # 输出第二个分组匹配的字符串 '45'
print(match.group(3)) # 输出第三个分组匹配的字符串 '6789'groups()
- groups() 方法返回一个包含所有分组匹配的文本的元组,不包括整个匹配的字符串。
- 如果正则表达式中没有分组,则返回一个空元组。
继续上面的例子:
print(match.groups()) # 输出 ('123', '45', '6789')这里,groups() 返回一个元组,包含了所有分组的匹配结果,但不包括整个匹配的字符串。
总结一下,group() 和 groups() 方法都用于从正则表达式匹配结果中提取信息,但它们在获取信息的粒度和方式上有所不同。group() 更加灵活,可以获取整个匹配的字符串或任意一个分组的匹配,而 groups() 用于获取所有分组的匹配结果。
5. 更多例子
下面我举了更多的例子,供大家练习和熟悉。
建议先自己尝试去写出相关的正则表达式,再回来看下面的参考答案。
- 匹配Email地址的正则表达式
- 匹配网址URL的正则表达式
- 匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线)
- 匹配国内电话号码(0571-87655322,001-87666622,920-209642-964)
- 匹配腾讯qq号
- 匹配中国邮政编码(6位数字)
- 匹配身份证(15位或18位)
- 匹配ip地址
- 形如"carcar"或"barbar"等会重复的三个字符的单词
爬取带有base64加密的网站
base64解密
import base64
# 假设这是你从网页中爬取到的Base64编码字符串
encoded_string = "SGVsbG8gV29ybGQh"
# 使用base64模块解码
decoded_bytes = base64.b64decode(encoded_string)
# 将bytes转换为字符串
decoded_string = decoded_bytes.decode('utf-8')
print(decoded_string)在这个例子中,encoded_string 应该替换为你从网页中获取的Base64编码内容。base64.b64decode() 函数用于解码这个字符串,返回的是字节数据,之后使用 .decode('utf-8') 将字节数据转换为字符串。
Base64 编码通常由 ASCII 字符组成,包括 A-Z、a-z、0-9、加号(+)和斜杠(/)
尝试base64解码
try:
# 尝试 Base64 解码
decoded_bytes = base64.b64decode(response.text)
print(decoded_bytes)
except base64.binascii.Error:
# 处理解码错误
print("解码错误:提供的数据不是有效的 Base64 编码。")
except Exception as e:
# 其他错误处理
print(f"发生错误:{str(e)}")解析本地html文件
from lxml import html
tree = html.parse('F:/study/网页学习/promise/promise.html')获取[后的数据
import re
# 示例字符串
text = "这是一个测试字符串[这是中括号内的内容]这是期望提取的内容。"
# 使用正则表达式找到 "]" 后面的所有字符
# 正则表达式解释:'(?<=])' 是一个正向后视断言,用于匹配 ']' 后的位置,'.*' 表示匹配任意数量的字符(除了换行符)
matches = re.search(r'(?<=\]).*', text)
# 检查是否有匹配项,并提取
if matches:
extracted_content = matches.group()
print(extracted_content)
else:
print("没有找到匹配内容")代码
import requests
from lxml import etree
import re
import base64
url = "http://c4.cccpan.com/f_ht/ajcx/wj.aspx?cz=dq&jsq=0&mlbh=1705927&wjpx=1&_dlmc=quruanpu&_dlmm="
headers = {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Connection": "keep-alive",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Cookie": "ASP.NET_SessionId=gau0vaim0rqebpwtuvigbrgb",
"Host": "c4.cccpan.com",
"Referer": "http://c4.cccpan.com/f_ht/ajcx/000ht.html?bbh=1173",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0"
}
response_content = requests.get(url, headers=headers).content
decoded_content = response_content.decode('utf-8')
posin = decoded_content.find(']')
extracted_content = decoded_content[posin+1:]
# 使用base64模块解码
decoded_bytes = base64.b64decode(extracted_content)
# 将bytes转换为字符串
decoded_string = decoded_bytes.decode('utf-8')
tree = etree.HTML(decoded_string)
li_list = tree.xpath('//li//ul[@class="menu"]/li[@class="xlj"]')
for i in li_list:
url_ = i.xpath('./a/@href')
print(url_)
# from lxml import etree
# #解析本地文件使用 etree.parse
# tree = etree.parse('F:/study/网页学习/promise/promise.html')
from lxml import html
import pandas as pd
tree = html.parse('F:/study/网页学习/promise/promise.html')
li_list = tree.xpath('/html/body/li[1]/ul/li')
data_list = []
for i in li_list:
url = i.xpath('./a[1]/@href')[0]
name = i.xpath('./a[1]/text()')[0]
data_list.append([name,url])
df = pd.DataFrame(data_list,columns=['名字','链接地址'])
df.to_excel('电视网站在线.xlsx',index=False)selenium
控制浏览器打开网页
# 导入 webdriver
from selenium import webdriver
from selenium.webdriver.common.by import By
# 调用键盘按键操作时需要引入的Keys包
from selenium.webdriver.common.keys import Keys
# 调用环境变量指定的PhantomJS浏览器创建浏览器对象
driver = webdriver.Chrome("./chromedriver.exe")
# get方法会一直等到页面被完全加载,然后才会继续程序,通常测试会在这里选择 time.sleep(2)
driver.get("http://www.baidu.com/")控制页面元素
# id="kw"是百度搜索输入框,输入字符串"长城"
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("长城")
# id="su"是百度搜索按钮,click() 是模拟点击
driver.find_element(By.CSS_SELECTOR,"#su").click()
# 关闭浏览器
driver.quit()常用操作
元素定位
获取单个元素
driver.find_element(By.ID,"inputOriginal")
driver.find_element(By.CSS_SELECTOR,"#inputOriginal")
driver.find_element(By.TAG_NAME,"div")
driver.find_element(By.NAME,"username")
driver.find_element(By.LINK_TEXT,"下一页")如果找不到相应的元素会报错
获取多个元素
driver.find_elements(By.ID,"inputOriginal")
driver.find_elements(By.CSS_SELECTOR,"#inputOriginal")
driver.find_elements(By.TAG_NAME,"div")
driver.find_elements(By.NAME,"username")
driver.find_elements(By.LINK_TEXT,"下一页")案例
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
#2. 内容获取
driver = webdriver.Chrome()
# 加载有道翻译页面
driver.get("https://fanyi.baidu.com/mtpe-individual/multimodal?ext_channel=DuSearch#/")
# 获取输入框
input = driver.find_element(By.XPATH,'//*[@id="editor-text"]/div[1]/div[1]/div/div/div')
# 输入内容
input.send_keys("hello")
# 获取翻译按钮
time.sleep(1)
# 发现页面被遮挡,此时无法点击
# tbtn.click()
# 先获取遮挡的广告条,点击关闭按钮
close_btn = driver.find_element(By.XPATH,'//*[@id="multiContainer"]/div[3]/div/div[2]/span')
close_btn.click()
#点击翻译
# tbtn.click()
#获取翻译后的内容
transTarget = driver.find_element(By.XPATH,'//*[@id="trans-selection"]/div')
print(transTarget.text)
driver.quit()内容获取
1. size 返回元素大小
2. text 获取元素的文本 <div>hello</div>
3. title 获取页面title
4. current_url 获取当前页面URL
5. get_attribute() 获取属性值 <a href="xxxx">百度</a>
6. is_display() 判断元素是否可见
7. is_enabled() 判断元素是否可用窗口操作
1. maximize_window() 最大化 --> 模拟浏览器最大化按钮
2. set_window_size(100,100) 浏览器大小 --> 设置浏览器宽、高(像素点)
3. set_window_position(300,200) 浏览器位置 --> 设置浏览器位置
4. back() 后退 --> 模拟浏览器后退按钮
5. forward() 前进 --> 模拟浏览器前进按钮
6. refresh() 刷新 --> 模拟浏览器F5刷新
7. close() 关闭 --> 模拟浏览器关闭按钮(关闭单个窗口)
8. quit() 关闭 --> 关闭所有WebDriver启动的窗口元素等待
翻页获取每页元素
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome("./chromedriver.exe")
# 加载当当网
driver.get("https://www.dangdang.com/")
# 获取输入框
key = driver.find_element(By.ID,"key_S")
key.send_keys("科幻")
# 获取搜索框,点击搜索
search = driver.find_element(By.CSS_SELECTOR,".search .button")
search.click()
# 获取商品标题及价格
for i in range(5):
shoplist = driver.find_elements(By.CSS_SELECTOR, ".shoplist li")
for li in shoplist:
print(li.find_element(By.CSS_SELECTOR, "a").get_attribute("title"))
# 获取下一页按钮
next = driver.find_element(By.LINK_TEXT, "下一页")
next.click()隐式等待
implicitly_wait(time_to_wait)设置的时间单位为秒,例如implicitly_wait(30),意思是超过30秒没有定位到一个元素,程序就会报错抛
出异常,期间会一直轮询查找定位元素。
JSON
js逆向 头条案例
编译js代码
python执行执行本地命令:node v1.js
import os
import subprocess
# 根据自己的操作系统去修改(相当于python的sys.path,加载安装的模块)
os.environ["NODE_PATH"] = "/usr/local/lib/node_modules/"
signature = subprocess.getoutput('node v1.js')pyexec.js编译代码
准备环境:
node.js
pyexecjs模块
pip install pyexecjs
例如:
v2.js
function func(arg) { return arg + '666'; }执行js代码
import execjs import os os.environ["NODE_PATH"] = "/usr/local/lib/node_modules/" with open('v2.js', mode='r', encoding='utf-8') as f: js = f.read() JS = execjs.compile(js) sign = JS.call("func", "微信") print(sign) # 微信666
浏览器环境
node.js
jsdom(通过后端node+js代码实现伪造浏览器环境)
npm install node-gyp@latest sudo npm explore -g npm -- npm i node-gyp@latest npm install jsdom -g注意:上述安装成功后已可以模拟浏览器环境,由于今天的头条他的内容。
npm install canvas -g
方式一:v10.js
const jsdom = require("jsdom");
const {JSDOM} = jsdom;
const resourceLoader = new jsdom.ResourceLoader({
userAgent: "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36",
});
const html = `<!DOCTYPE html><p>Hello world</p>`;
const dom = new JSDOM(html, {
url: "https://www.toutiao.com",
referrer: "https://example.com/",
contentType: "text/html",
resources: resourceLoader,
});
console.log(dom.window.location)
console.log(dom.window.navigator.userAgent)
console.log(dom.window.document.referrer)import os
import subprocess
# 根据自己的操作系统去修改(相当于python的sys.path,加载安装的模块)
os.environ["NODE_PATH"] = "/usr/local/lib/node_modules/"
res = subprocess.getoutput('node v10.js')方式2:无法补充环境时
const jsdom = require("jsdom");
const {JSDOM} = jsdom;
const resourceLoader = new jsdom.ResourceLoader({
userAgent: "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36"
});
const html = `<!DOCTYPE html><p>Hello world</p>`;
const dom = new JSDOM(html, {
url: "https://www.toutiao.com",
referrer: "https://example.com/",
contentType: "text/html",
resources: resourceLoader,
});
/*
console.log(dom.window.location)
console.log(dom.window.navigator.userAgent)
console.log(dom.window.document.referrer)
*/
window = global;
const params = {
location: {
hash: "",
host: "www.toutiao.com",
hostname: "www.toutiao.com",
href: "https://www.toutiao.com",
origin: "https://www.toutiao.com",
pathname: "/",
port: "",
protocol: "https:",
search: "",
},
navigator: {
appCodeName: "Mozilla",
appName: "Netscape",
appVersion: "5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36",
cookieEnabled: true,
deviceMemory: 8,
doNotTrack: null,
hardwareConcurrency: 4,
language: "zh-CN",
languages: ["zh-CN", "zh"],
maxTouchPoints: 0,
onLine: true,
platform: "MacIntel",
product: "Gecko",
productSub: "20030107",
userAgent: "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36",
vendor: "Google Inc.",
vendorSub: "",
webdriver: false
}
};
Object.assign(global,params)
# 在下面如果你使用
location.href
navigator.appCodeName
window.location.href
window.appCodeName注意:在nodejs中默认代码中会有一个global的关键字(全局变量)。
v1 = 123;
console.log(global);global.v1 = 123
global.v2 = 123
global.navigator = {
...
}
console.log(v1,v2);
navigator.userAgent