Hadoop
一、前置操作
【Hadoop】它是开源大数据的技术框架之一
它底层是基于Java语言开发的。这就意味着我们想要运行它,就需要Java运行时环境。
Java常见的运行环境有?
JRE:Java Runtime Enviroment:Java运行时环境
Runtime:运行时
Enviroment:环境
JDK:Java Development Kits:Java开发工具集
Development:n,开发/发展
Kit:工具箱/工具包
JRE和JDK之间的关联?
JDK包含JRE。
1.1、创建文件夹
在【/opt/】目录下手动创建两个文件夹分别为:【softwares】、【uploads】
【softwares】:软件(们),它就只用来存放解压出来的软件(技术框架、架构、程序)
【uploads】:上传,它就只用来存放我们上传到虚拟机(服务器)系统的文件/软件
【mkdir】
mk —— make,做
dir —— directory,文件夹/目录
语法:
【mkidr 文件夹的名称】
具体的命令:
mkdir softwares
mkdir uploads或者
mkdir softwares && mkdir uploads二、安装Hadoop
2.1、上传jdk和压缩包
切换到uploads文件下
安装上传下载工具
yum install -y lrzsz
2.2、解压
tar命令选项:
用于解压某个文件的命令选项组合为:【-zxvf】
用于压缩某个文件的命令选项组合为:【-zcvf】
-C:用于告诉【tar】命令解压到哪个具体路径下
语法形式:
【tar 命令选项 压缩文件的名称】
具体命令:
tar -zxvf jdk压缩包的名称 -C /opt/softwares2.3、配置环境变量
2.3.1、JDK环境变量
vi /etc/profile.d/myenv.shmyenv.sh文件是不存在的
【vi】命令的一个特点:
如果你编辑的对象是一个不存在的文件,那么vi命令会帮你创建/新建
所以【vi /etc/profile.d/myenv.sh】这条命令本质上是新建了一个叫做【myenv.sh】的文件
.sh:shell脚本文件,shell大家可以简单的理解为一种开发语言(类似于Java、C等)
export JAVA_HOME=/opt/softwares/jdk1.8.0_121配置项的含义:
我们告诉系统,JDK存放到了哪里
export PATH=$PATH:$JAVA_HOME/bin配置项的含义:
$:取值
【PATH】:系统【环境】变量
【JAVA_HOME】:用户变量
:分隔符没有特别含义
export 使什么生效
source /etc/profile.d/my_env.sh # 通过这条命令使配置生效
java -version # 测试配置是否成功
2.3.2、Hadoop环境变量
vi /etc/profile.d/myenv.sh
export HADOOP_HOME=/opt/softwares/hadoop-3.1.3
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin保存并
source /etc/profile.d/my_env.sh2.4、配置免密登录
修改hosts文件
形式:
【ip地址 url】
本质上是通过DNS服务器将URL转换成IP地址的
【ssh-keygen -t rsa】:以RSA加密算法在本地生成对应的密钥文件
id_rsa:私钥文件(钥匙)
id_rsa.pub:公钥文件(锁)
分发秘钥,分发的是公钥
yum install -y openssh-clients命令安装【openssh-clients】
ssh-keygen -t rsa在本地生成密钥文件(3次回车)
ssh-copy-id root@bigdata01将秘钥分发给主机名为【bigdata01】的root用户上
ssh root@主机名验证免密登录是否配置成功
2.5、修改配置文件
修改Hadoop自身的配置文件来完成【Hadoop单机部署/Standalone】
2.5.1、必须修改的配置文件
【core-site.xml】
core:核心
core-site.xml:主要针对Hadoop核心模块进行设置(通用)
【hdfs-site.xml】
hdfs:
Hadoop:开源大数据的框架
Distributed :分布式的
File:文件
System: 系统
hads-site.xml:主要针对Hadoop的HDFS模块进行配置
【workers】
workers:针对Hadoop的工作者进行配置2.5.2、可选修改的配置文件
【yarn-site.xml】
yarn:就是Hadoop一个模块,资源管理模块
【mapred-site.xml】
mapred:map和reduce的简写,mapreduce是hadoop的一个模块,计算模块2.5.3、注释
html中的注释
多行注释java中的注释
单行注释 //注释内容
多行注释 /* 注释内容 */
文档注释 /** 注释内容 */
2.5.4、vi/vim快捷键
dd:快速删除当前光标所在行的内容
shfit+G : 快速跳转到文档的末尾
ML:Markdown Language :标记语言
2.5.5、配置hadoop
①core-site.xml
<configuration>
<property>
<!--指定 namenode 的 hdfs 协议文件系统的通信地址-->
<name>fs.defaultFS</name>
<value>hdfs://bigdata01:8020</value>
</property>
<property>
<!--指定 hadoop 存储临时文件的目录-->
<name>hadoop.tmp.dir</name>
<value>/opt/softwares/hadoop-3.1.3/tmpDatas</value>
</property>
</configuration>8020:Hadoop的HDFS模块中的Name服务的通信地址
hdfs://bigdata01:8020hdfs://ip地址:port端口号
②hdfs-site.xml
<configuration>
<property>
<!--由于我们这里搭建是单机版本,所以指定 dfs 的副本系数为 1-->
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>replication: 副本
③workers
改成主机名
2.6、添加映射
使用vim /etc/hosts 来修改hosts文件
格式:
ip 主机名
2.7、初始化
初始化Hadoop【HDFS】 ——》Namenode
2.8、启动hadoop
- 启动命令:[start-dfs.sh]
.sh表示该文件是一个shell脚本文件
- 为什么可以直接执行[start-dfs.sh] 命令
配置了环境变量
- 验证是否启动成功
jps出现一下几条,则说明启动成功
Jps
DataNode
SecondaryNameNode
NameNode
- stop-dfs.sh命令关闭所有HDFS相关的服务
①访问web端
port:9870
②常见端口号
HDFS的通信端口号:8020
HTTP端口(前端页面):9870
③前端页面简介
 Cluster:集群
Cluster:集群
Cluster ID:集群ID
④Hadoop启动流程
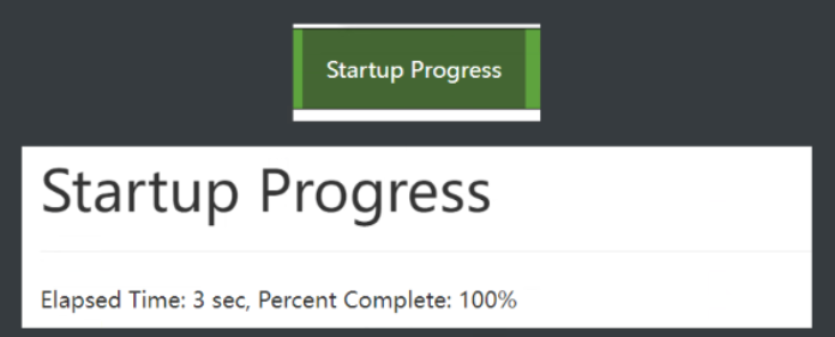
1、加载FSlmage文件(Hadoop快照文件)
2、加载Edits文件(操作日志文件)
3、保存CheckPoint文件 (检查点)
4、退出Safe Mode(安全模式)
启动出错,可能由于安全模式还没有退出导致的
三、回顾
安装部署Hadoop(standalone模式)总体流程:
1)、编辑hosts文件,添加ip地址和主机名之间的映射关系
2)、配置免密登录(避免不能模块之间的通信堵塞)
3)、配置环境变量
4)、修改Hadoop自身配置文件(core-site.xml、hdfs-site.xml、workers、yarn-site.xml、mapred-site.xml)
5)、对HDFS进行格式化
6)、通过 [start-dfs.sh]启动Hadoop(HDFS)
大数据所需技术栈