
pandas
比赛
import pandas as pd
# 加载数据集
df = pd.read_csv("/data/SecondhandHouse.csv")
# 原始数据集的行列数
original_shape = df.shape
# 用null值替换数据中含有“暂无”两字的信息,再删除含有null的行数据
df.replace('暂无', pd.NA, inplace=True)
df.dropna(inplace=True)
# 删除null值后数据集的行列数
after_dropna_shape = df.shape
# 统计行数据重复的数量
duplicates_count = df.duplicated().sum()
# 删除重复的行数据
df.drop_duplicates(inplace=True)
# 删除重复数据后数据集的行列数
after_drop_duplicates_shape = df.shape
# 删除“建筑面积”列的面积单位“平米”,仅保留数值,并转为浮点型
df['建筑面积'] = df['建筑面积'].str.replace('平米', '').astype(float)
# 删除“建筑年代”列的年份单位“年”,仅保留数值,并转为整型
df['建筑年代'] = df['建筑年代'].str.replace('年', '').astype(int)
# 保留“建筑年代”小于等于2021年的房屋数据
df = df[df['建筑年代'] <= 2021]
# 处理后数据集的行列数
after_year_filter_shape = df.shape
# 提取“户型”列中的室、厅、卫的数量
#df[['室', '厅', '卫']] = df['户型'].str.extract('(%d)室(%d)厅(%d)卫').astype(int)
df[['室', '厅', '卫']] = df['户型'].str.extract('(\d+)室(\d+)厅(\d+)卫').astype(int)
# 使用当前年份(2022年)减去建筑年份获取房龄,并存入“房龄”列
df['房龄'] = 2022 - df['建筑年代']
# 输出处理步骤的结果
print(original_shape)
print(after_dropna_shape)
print(duplicates_count)
print(after_drop_duplicates_shape)
print(after_year_filter_shape)
df.to_csv('/data/result.csv', index=False)准考证号:手机号+20240417
密码:240417
pandas读取数据
| 数据类型 | 说明 | Pandas读取方法 |
|---|---|---|
| tsv、txt、csv、 | 用逗号分隔、tab分割的纯文本文件 | pd.read_csv |
| excel | 微软xls或者xlsx文件 | pd.read_excel |
| mysql | 关系型数据库表 | pd.read_sql |
.head 返回前几行
.shape 返回行数列数
.columns返回列名
.index返回索引
.dtype查看类型
读取txt文件,自己指定分割符,列名
pd.read.csv(
path,
sep="\t",
header=None,
names=['1','2','3']
)读取mysql
import pymysql
conn = pymysql.connect(
host='127.0.0.1',
uesr='root',
password='123456',
database='test',
charset='utf8'
)
mysql_page = pd.read_sql("select * from name",con=conn)数据结构
DataFrame & Series
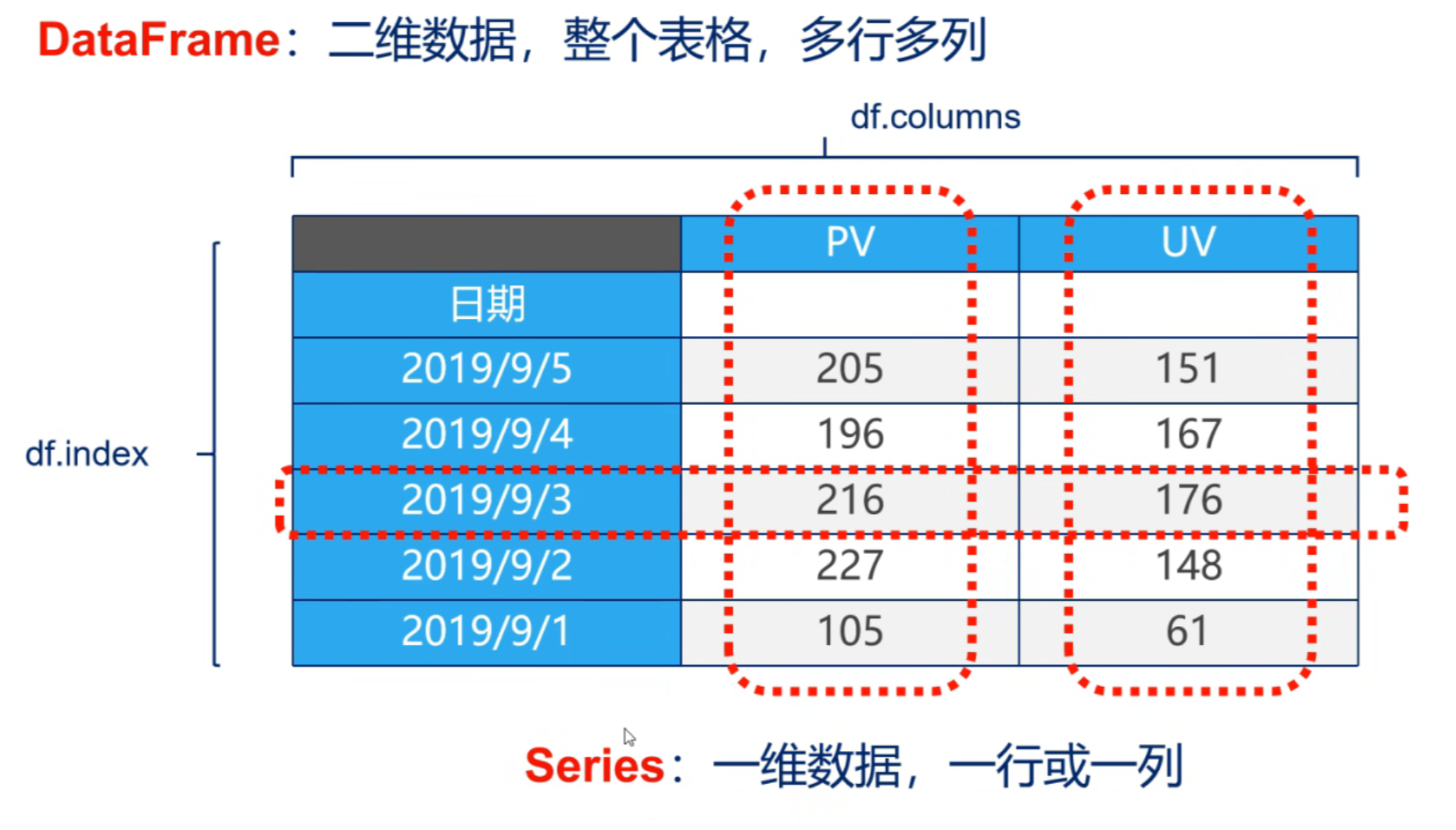 "
"
1、Series
Series是一种类似于一维数组的对象,它由一组数据(不同数据类型)以及一组与之相关的数据标签(即索引)组成。
pd.Series(data=None, index=None, dtype=None, name=None, copy=False)
- data 输入的数据,可以是列表、常量、ndarray 数组等,如果是字典,则保持参数顺序
- index 索引值,必须是可散列的(不可变数据类型(str,bytes和数值类型)),并且与数据具有相
- 同的长度,允许使用非唯一索引值。如果未提供,将默认为RangeIndex(0,1,2,…,n)
- dtype 输出系列的数据类型。如果未指定,将从数据中推断
- name 为Series定义一个名称
- copy 表示对 data 进行拷贝,默认为 False,仅影响Series和ndarray数组
列表/数组作为数据源创建Series
S1 = pd.Series([1,'a',5.2,7])
S1
0 1
1 a
2 5.2
3 7
dtype:object
通过index 和values属性取得对应的标签和值
获取索引
S1.index
获取数据
S1.values
通过标签取得对应的值,或者修改对应的值
s1[1] # 取得索引为1 的数据
s1[2] = 50 # 改变索引为2的数据值字典作为数据源创建Series
sdata={'oh':3500,'te':7200,'or':160,'ui':222}
s3=pd.Series(sdata)
获取值
s2['a']
s2[0]
多值
s2[['a','b']]
index参数
创建一个具有标签索引的Series
s2 = pd.Series([1,'a',5.2,7],index=['a','b','c','d'])
当传递的索引值未匹配对应的字典键时,使用 NaN(非数字)填充。
d = {'a': 1, 'b': 2, 'c': 3}
ser = pd.Series(data=d, index=['x', 'b', 'z'])
通过匹配的索引值,改变创建Series数据的顺序
d = {'a': 1, 'b': 2, 'c': 3}
ser = pd.Series(data=d, index=['c', 'b', 'a'])
ser
name参数
我们可以给一个Series对象命名,也可以给一个Series数组中的索引列起一个名字,pandas为我们设计好了对象的属性,并在设置了name属性值用来进行名字的设定
dict_data1 = {
"Beijing":2200,
"Shanghai":2500,
"Shenzhen":1700
}
data1 = pd.Series(dict_data1)
data1
data1 = pd.Series(dict_data1)
data1.name= "City_Data"
data1.index.name= "City_Name"
Series的索引/切片
1、下标索引
2、标签索引
Series数据结构 基本技巧
1. 查看前几条和后几条数据
s = pd.Series(np.random.rand(15))
print(s.head()) # 默认查看前5条数据
print(s.head(1)) # 默认查看前1条数据
print(s.tail()) # 默认查看后5条数据
2. 重新索引**: reindex**
s = pd.Series(np.random.rand(5),index=list("abcde"))
\# 新索引在上一个索引中不存在,生成新对象时,对应的值,设置为NaN
s1 = s.reindex(list("cde"))
\# 设置填充值
s2 = s.reindex(list("cde12"), fill_value=0)
print(s2)
对齐运算
是数据清洗的重要过程,可以按索引对齐进行运算,如果没对齐的位置则补NaN,最后也可以填充NaN
s1 = pd.Series(np.random.rand(3), index=["Kelly","Anne","T-C"])
s2 = pd.Series(np.random.rand(3), index=["Anne","Kelly","LiLy"])
删除和添加
删除
s = pd.Series(np.random.rand(5),index=list("abcde"))
s1 = s.drop("a") # 返回删除后的值,原值不改变 ,默认inplace=False
s = pd.Series(np.random.rand(5),index=list("abcde"))
s1 = s.drop("a",inplace=True) # 原值发生变化,返回None
\#s = s.drop("a")
\# inplace默认默认为True,返回None
添加
import pandas as pd
\# 添加
s1 = pd.Series(np.random.rand(5),index=list("abcde"))
s1["s"] = 100 # 对应的标签没有就是添加,,有就是修改
DataFrame

DataFrame是一个表格型的数据结构
- 每列可以是不同的值类型(数值、字符串、布尔值等)
- 既有行索引index,也有列索引columns
- 可以被看做由Series组成的字典
创建dataframe最常用的方法,见02节读取纯文本文件、excel、mysql数据库
pandas.DataFrame(data=None, index=None, columns=None, dtype=None,
copy=None)
- data: 输入的数据,可以是 ndarray,series,list,dict,标量以及一个 DataFrame
- index: 行标签,如果没有传递 index 值,则默认行标签是 RangeIndex(0, 1, 2, …,n),n 代表 data 的元素个数。
- columns: 列标签,如果没有传递 columns 值,则默认列标签是 RangeIndex(0, 1,2, …, n)。
- dtype: 要强制的数据类型。只允许使用一种数据类型。如果没有,自行推断
- copy: 从输入复制数据。对于dict数据,copy=True,重新复制一份。对于DataFrame或ndarray输入,类似于copy=False,使用的是试图
使用普通列表创建
data = [1,2,3,4,5]
df = pd.DataFrame(data)
使用嵌套列表创建
\# 列表中每个元素代表一行数据
data = [['xiaowang',20],['Lily',30],['Anne',40]]
\# 未分配列标签
df = pd.DataFrame(data)
data = [['xiaowang',20],['Lily',30],['Anne',40]]
\# 分配列标签
df = pd.DataFrame(data,columns=['Name','Age'])
根据多个字典序列创建dataframe
# 字典.3.6之前是没有的 key ˱ >values 变量: 变量携带数据位置
# 3.7以后是有顺序的.
data = {'Name':['**关羽**', '**刘备**', '**张飞**', '**曹操**'],'Age':[28,34,29,42]}
# 通过字典创建DataFrame
df = pd.DataFrame(data)
print(df)
\# **输入标签**
print(df.index)
添加自定义行标签
`# 字典`
data = {'Name':['**关羽**', '**刘备**', '**张飞**', '**曹操**'],'Age':[28,34,29,42]}
\# **定义行标签**
index = ["rank1", "rank2", "rank3", "rank4"]
\# **通过字典创建**DataFrame
df = pd.DataFrame(data, index=index)
print(df)
\# **输入行标签**
print(df.index)
\# **输出列表标签**
print(df.columns)
列表嵌套字典创建DataFrame对象
列表嵌套字典可以作为输入数据传递给 DataFrame 构造函数。默认情况下,字
典的键被用作列名。
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
\#df = pd.DataFrame(data)
df = pd.DataFrame(data, index=['first', 'second'])
print(df)
a b c
first 1 2 NaN
second 5 10 20.0
Series创建DataFrame对象
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
one two
a 1.0 1
b 2.0 2
c 3.0 3
d NaN 4
# 创建数据
data = {
"Name":pd.Series(['xiaowang', 'Lily', 'Anne']),
"Age":pd.Series([20, 30, 40], dtype=float),
"gender":pd.Series(["男", "男", "女"]),
"salary":pd.Series([5000, 8000, 10000], dtype=float)
}
df = pd.DataFrame(data)
# int满足某列特征,会自动使用, 不满足,则自动识别
df
# 解决不同列 设置自定义数据类型
查询列
df[['yeaer','pop']]
# 注意列不是能使用切片选取多列
列添加
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
#使用df['列']=值,插入新的数据列
print ("通过Series添加一个新的列😊
df['three']=pd.Series([10,20,30],index=['a','b','c'])
print(df)
#将已经存在的数据列相加运算,从而创建一个新的列
print ("将已经存在的数据列相加运算,从而创建一个新的列:=")
df['four']=df['one']+df['three']
print(df)
insert() 方法插入新的列
df.insert(loc, column, value, allow_duplicates=False)
loc : 整型**,插入索引,必须验证0<=loc<=len**(列)
column : 插入列的标签**,类型可以是(字符串/数字/散列对象)**
value : 数值**,Series**或者数组
allow_duplicates : 允许重复**,可以有相同的列标签数据,默认为False**
info=[['王杰',18],['李杰',19],['刘杰',17]]
df=pd.DataFrame(info,columns=['name','age'])
print(df)
#注意是column参数
#数值1代表插入到columns列表的索引位置
df.insert(2,column='score',value=[91,90,75])
print("=df.insert插入数据:===")
print(df)
删除数据列
通过 del 和 pop() 都能够删除 DataFrame 中的数据列**,pop**有返回值
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd']),
'three' : pd.Series([10,20,30], index=['a','b','c'])}
df = pd.DataFrame(d)
print ("Our dataframe is:")
print(df)
#使用del删除
del df['one']
print("=del df['one']===")
print(df)
#使用pop方法删除
res_pop = df.pop('two')
print("=df.pop('two')===")
print(df)
print("=res_pop = df.pop('two')===")
print(res_pop)
查询行
import pandas as pd
# 定义字典
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
# 创建DataFrame数据结构
df = pd.DataFrame(d)
print("===df原始数据")
print(df)
# 确定标签为b的数据
print("===标签为b的数据")
print(df.loc['b'])
df.loc['b',"one"] 行列 交叉点
行和列还可以使用切片
# 标签为b的行到标签为d的行, 对应标签为one的列
df.loc['b':'d',"one"] # 注意使用行标签切片,包含结束的行
# 注意这里和numpy整数数组索引区别
df.loc[['a','b'],["one","two"]] # 这里两个参数,第一个代表行,第二个代表列
数值型索引和切片
可以使用iloc **😗*行基于整数位置的按位置选择索引
# 取得位置索引为2的数据
df.iloc[2]
# 取得位置索引分别为0和2的数据
df.iloc[[0,2]]
# 表示行索引为0,列索引为1的数据
df.iloc[0,1]
# 取得位置索引1到3行,但是不包含3的数据
print("=df.iloc[1:3]:===")
print(df.iloc[1:3])
# 使用切片可以直接提取行
print("=df[1:3]:===")
print(df[1:3])
**.**添加数据行
使用 append() 函数,可以将新的数据行添加到 DataFrame 中,该函数会在行末追加数
据行
df.append(other, ignore_index=False, verify_integrity=False,sort=False)
将**"other"追加到调用者的末尾,返回一个新对象。"other"**行中不在调用者中的列将作为
新列添加。
- other : DataFrame或Series/dict类对象,或这些对象的列表
- ignore_index : 默认为False,如果为True将不适用index 标签**.**
- verify_integrity : 默认为False如果为True,则在创建具有重复项的索引时引发ValueError.
- sort : 排序
import pandas as pd
data = {
'Name':['关羽', '刘备', '张飞', '曹操'],
'Age':[28, 34, 29, 42],
"Salary":[5000, 8000, 4500, 10000]
}
df = pd.DataFrame(data)
df
追加字典
d2 = {"Name":"诸葛亮", "Age":30}
#在行末追加新数据行
df3 = df.append(d2) # 需要添加 ignore_index=True,不然会报错
print(df3)
Series数据有name
d2 = {"Name":"诸葛亮", "Age":30}
s = pd.Series(d2, name="a")
print(s)
#在行末追加新数据行
df3 = df.append(s) # 需要添加
print(df3)
Name 诸葛亮
Age 30
Name: a, dtype: object
Name Age Salary
0 关羽 28 5000.0
1 刘备 34 8000.0
2 张飞 29 4500.0
3 曹操 42 10000.0
a 诸葛亮 30 NaN
追加列表
追加列表
注意:使用append可能会出现相同的index,想避免的话,可以使用ignore_index=True
- 如果list是一维的**,**则以列的形式追加
- 如果list是二维的**,**则以行的形式追加
- 如果list是三维的**,**只添加一个值
list是二维的**,**则以行的形式追加
a_l = [[10,"20",30],[2,5,6]]
df4 = df.append(a_l) # 需要添加
print(df4)
data = {
'Name':['关羽', '刘备', '张飞', '曹操'],
'Age':[28, 34, 29, 42],
"Salary":[5000, 8000, 4500, 10000]
}
df = pd.DataFrame(data)
a_l = [[10,"20",30],[2,5,6]]
df2 = pd.DataFrame(a_l,columns=["Name","Age","Salary"]) #需要指定列名,不然对不齐
# 将df2追加到df中返回
df4 = df.append(df2) # 需要添加
print(df4)
data = [
[1, 2, 3, 4],
[5, 6, 7, 8]
] #列表默认的列名为0,1,3所以添加a_l时能对齐列
df = pd.DataFrame(data)
print(df)
a_l = [[10,"20",30],[2,5,6]]
df5 = df.append(a_l,ignore_index=True)
df5
list是一维**,**则以列的形式追加
data = [
[1, 2, 3, 4],
[5, 6, 7, 8]
]
df = pd.DataFrame(data)
print(df)
a_l = [10,20]
df3 = df.append(a_l) # 需要添加
print(df3)
0 1 2 3
0 1 2.0 3.0 4.0
1 5 6.0 7.0 8.0
0 10 NaN NaN NaN
1 20 NaN NaN NaN
删除数据行
您可以使用行索引标签,从 DataFrame 中删除某一行数据。如果索引标签存在重复,那
么它们将被一起删除。
df = pd.DataFrame([[1, 2], [3, 4]], columns = ['a','b'])
df2 = pd.DataFrame([[5, 6], [7, 8]], columns = ['a','b'])
df = df.append(df2)
print("=源数据df=")
print(df)
#注意此处调用了drop()方法,注意drop默认不会更改源数据
df1 = df.drop(0)
print("=修改后数据df1=")
print(df1)
# 两种方式解决:
# 1. 源数据=修改后的数据
df = df.drop(0)
# 2.添加inplace=True
df = df.drop(1)
常用属性和方法汇总
| 名称 | 属性**&**方法描述 |
|---|---|
| T | 行和列转置。 |
| axes | 返回一个仅以行轴标签和列轴标签为成员的列表。 |
| dtypes | 返回每列数据的数据类型 |
| empty | DataFrame中没有数据或者任意坐标轴的长度为0,则返回True |
| columns | 返回DataFrame所有列标签 |
| shape | 返回一个元组,获取行数和列数,表示了 DataFrame 维度 |
| size | DataFrame中的元素数量 |
| values | 使用 numpy 数组表示 DataFrame 中的元素值。 |
| head() | 返回前 n 行数据。 |
| tail() | 返回后 n 行数据。 |
| rename() | rename(columns=字典) ,修改列名 |
| info() | 可以显示信息,例如行数/列数,总内存使用量,每列的数据类型以及不缺少值的元素数 |
| sort_index() | 默认根据行标签对所有行排序,或根据列标签对所有列排序,或根据指定某列或某几列对行排序。 |
| sort_values() | 既可以根据列数据,也可根据行数据排序 |
修改标签名rename()
DataFrame.rename(index=None, columns=None, inplace=False)
- index: 修改后的行标签
- columns: 修改后的列标签
- inplace: 默认为False,不改变源数据,返回修改后的数据. True更改源数据
# 修改变量df的行标签
df.rename(index={1:"row2", 2:"row3"})
# 修改变量df的列标签
df.rename(columns = {"Name":"name", "Age":"age"})
# 添加inplace参数,修改原数据
df.rename(index={1:"row2", 2:"row3"}, columns = {"Name":"name",
"Age":"age"}, inplace=True)
df. sort_index()
sort_index(axis=0, ascending=True, inplace=False)
作用:默认根据行标签对所有行排序,或根据列标签对所有列排序,或根据指定某列或
某几列对行排序。
注意:df.sort_index()可以完成和df.sort_values()完全相同的功能,但python更推荐用只用
df.sort_index()对“根据行标签”和“根据列标签”排序,其他排序方式用df.sort_values()。
- axis:0按照行名排序;1按照列名排序
- ascending:默认True升序排列;False降序排列
- inplace:默认False,否则排序之后的数据直接替换原来的数据
import pandas as pd
# 创建示例DataFrame
df = pd.DataFrame({
'A': [3, 1, 2],
'B': [6, 5, 4]
}, index=['b', 'c', 'a'])
# 按索引升序排序
sorted_df = df.sort_index()
print("按行索引排序:")
print(sorted_df)
# 按列标签升序排序
sorted_df_columns = df.sort_index(axis=1)
print("\n按列索引排序:")
print(sorted_df_columns)df.sort_values()
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False,
kind='quicksort', na_position='last')
作用:既可以根据列数据,也可根据行数据排序。
注意:必须指定by参数,即必须指定哪几行或哪几列;无法根据index名和columns名排
序(由**.sort_index()**执行)
- by:str or list of str;如果axis=0,那么by="列名";如果axis=1,那么by="行名"。
- axis:{0 or ‘index’, 1 or ‘columns’}, default 0,默认按照列排序,即纵向排序;如果为1,则是横向排序。
- ascending:布尔型,True则升序,如果by=['列名1','列名2'],则该参数可以是**[True,False]**,即第一字段升序,第二个降序。
- inplace:布尔型,是否用排序后的数据框替换现有的数据框。
- na_position:{‘first’, ‘last’}, default ‘last’,默认缺失值排在最后面。
import pandas as pd
# 创建示例DataFrame
df = pd.DataFrame({
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 20, 30],
'Score': [88, 92, 85]
})
# 按年龄升序排序
sorted_df = df.sort_values(by='Age')
print("按年龄排序:")
print(sorted_df)
# 按分数降序排序
sorted_df_desc = df.sort_values(by='Score', ascending=False)
print("\n按分数降序排序:")
print(sorted_df_desc)# 源数据
df = pd.DataFrame({'b':[1,2,3,2],'a':[4,3,2,1],'c':[1,3,8,2]},index=
[2,0,1,3])
df
按b列升序排序
#等同于df.sort_values(by='b',axis=0)
df.sort_values(by='b')
先按b列降序,再按a列升序排序
df.sort_values(by=['b','a'],ascending=[False,True])
#等同于df.sort_values(by=['b','a'],axis=0,ascending=[False,True])
按行3升序排列
df.sort_values(by=3,axis=1) #必须指定axis=1
按行3升序,行0降排列
df.sort_values(by=[3,0],axis=1,ascending=[True,False])
time模块
不牵扯时区的问题,便于计算
- a、timestamp时间戳,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量
- b、struct_time时间元组,共有九个元素组。
- c、format time 格式化时间,已格式化的结构使时间更具可读性。包括自定义格式和固定格式。
时间格式转换图:

1.时间戳到结构化时间
import time
# 当前时间戳
timestamp = time.time()
# 转换为结构化时间
struct_time = time.localtime(timestamp)
print(struct_time)
2. 结构化时间到格式化时间
# 使用strftime格式化结构化时间
format_time = time.strftime('%Y-%m-%d %H:%M:%S', struct_time)
print(format_time)
3. 格式化时间到时间戳
# 使用strptime解析格式化时间为结构化时间
parsed_time = time.strptime(format_time, '%Y-%m-%d %H:%M:%S')
# 从结构化时间转换为时间戳
timestamp_from_format = time.mktime(parsed_time)
print(timestamp_from_format)主要time生成方法和time格式转换方法实例
# 导入time模块
import time
# 生成timestamp
time.time()
#格式化字符串到 struct_time
time.strptime('2011-05-05 16:37:06', '%Y-%m-%d %X')
struct_time元组元素结构
| 属性 | 值 |
|---|---|
| tm_year(年) | 比如2011 |
| tm_mon(月) | 1 - 12 |
| tm_mday(日) | 1 - 31 |
| tm_hour(时) | 0 - 23 |
| tm_min(分) | 0 - 59 |
| tm_sec(秒) | 0 - 61 |
| tm_wday(weekday) | 0 - 6(0表示周日) |
| tm_yday(一年中的第几天) | 1 - 366 |
| tm_isdst(是否是夏令时) | 默认为-1 |
作用:
- 取得 时间戳/时间格式的字符串 中对应的 年/月/日等信息
- 作为时间戳和字符串时间之间的桥梁
time_stuct = time.strptime('2011-05-07 16:37:06', '%Y-%m-%d %X')
print(time_stuct.tm_year)
print(time_stuct.tm_mon)
print(time_stuct.tm_mday)
print(time_stuct.tm_hour)
print(time_stuct.tm_min)
my = 'aaa'
'%s'% my
my_int = 1
'%d'% my_int
"我们在{}工作".format('家里')
addr = "家里"
f"我们在{addr}工作"
format time结构化表示
格式 含义
%Y -年[0001,...,2018,2019,...,9999]
%m -月[01,02,...,11,12]
%d -天[01,02,...,30,31]
%H -小时[00,01,...,22,23
%M -分钟[00,01,...,58,59]
%S -秒[00,01,...,58,61]
%X 本地相应时间
%y 去掉世纪的年份(00 - 99)
datetime模块
datatime模块重新封装了time模块,提供更多接口,提供的类有:
date,time,datetime,timedelta,tzinfo
date类
datetime.date(year, month, day)
静态方法和字段
- date.today():返回一个表示当前本地日期的date对象;
- date.fromtimestamp(timestamp):根据给定的时间戮,返回一个date对象;
from datetime import *
import time
print('date.today():', date.today())
print('date.fromtimestamp():', date.fromtimestamp(time.time()))
date.today(): 2024-03-31
date.fromtimestamp(): 2024-03-31方法和属性
d1 = date(2011,06,03) #date对象
- d1.year、date.month、date.day:年、月、日;
- d1.replace(year, month, day):生成一个新的日期对象,用参数指定的年,月,日
- 代替原有对象中的属性。(原有对象仍保持不变)
- d1.timetuple():返回日期对应的time.struct_time对象;
- d1.weekday():返回weekday,如果是星期一,返回0;如果是星期2,返回1,以此类推;
- d1.isoweekday():返回weekday,如果是星期一,返回1;如果是星期2,返回2,以此类推;
- d1.isoformat():返回格式如'YYYY-MM-DD’的字符串;
- d1.strftime(fmt):和time模块format相同。
now = date(2021, 10, 26)
print(now.year,now.month,now.day)
tomorrow = now.replace(day = 27)
print('now:', now, ', tomorrow:', tomorrow)
print('timetuple():', now.timetuple())
print('weekday():', now.weekday())
print('isoweekday():', now.isoweekday())
print('isoformat():', now.isoformat())
print('strftime():', now.strftime("%Y-%m-%d"))**.**时间转化
to_datetime 转换时间戳
你可能会想到,我们经常要和文本数据(字符串)打交道,能否快速将文本数据转为
时间戳呢?
to_datetime(arg, errors='raise', dayfirst=False, yearfirst=False,
utc=None, format=None, unit=None, infer_datetime_format=False,
origin='unix')
函数用户将数组、序列或dict的对象转换为datetime对象
- arg 要转换为日期时间的对象
- errors :错误处理
- If 'raise',将引发异常.
- If 'coerce', 无效的转换,使用NaT.
- If 'ignore', 无效的转换,将使用输入的数据.
- dayfirst :转换时指定日期分析顺序 yearfirst
- utc :控制与时区相关的解析、本地化和转换(忽略)
- format : 用于分析时间的strftime,例如“%d/%m/%Y”,自定义格式
- unit : D,s,ms 将时间戳转datetime
- origin : 定义参考日期。数值将被解析为自该参考日期起的单位数
# origin参考起始时间
pd.to_datetime([1, 2, 3], unit='D', origin=pd.Timestamp('2020-01-11'))
DatetimeIndex(['2020-01-12', '2020-01-13', '2020-01-14'],
dtype='datetime64[ns]', freq=None)
pd.to_datetime([1, 2, 3], unit='d')
DatetimeIndex(['1970-01-02', '1970-01-03', '1970-01-04'],
dtype='datetime64[ns]', freq=None)
# origin参考起始时间
pd.to_datetime([1, 2, 3], unit='h', origin=pd.Timestamp('2020-01'))
DatetimeIndex(['2020-01-01 01:00:00', '2020-01-01 02:00:00',
'2020-01-01 03:00:00'],
dtype='datetime64[ns]', freq=None)
# origin参考起始时间 m--分钟
pd.to_datetime([1, 2, 3], unit='m', origin=pd.Timestamp('2020-01'))
DatetimeIndex(['2020-01-01 00:01:00', '2020-01-01 00:02:00',
'2020-01-01 00:03:00'],
dtype='datetime64[ns]', freq=None)
# origin参考起始时间 m--分钟
pd.to_datetime([1, 2, 3], unit='s', origin=pd.Timestamp('2020-01'))
DatetimeIndex(['2020-01-01 00:00:01', '2020-01-01 00:00:02',
'2020-01-01 00:00:03'],
dtype='datetime64[ns]', freq=None)
不可转换日期/时间
如果日期不符合时间戳限制,则传递errors='ignore'将返回原始输入,而不是引发任何
异常。
除了将非日期(或不可解析的日期)强制传递给NaT之外,传递errors='coerce'还会将越
界日期强制传递给NaT
errors`:错误处理
If 'raise',将引发异常.
If 'coerce', 无效的转换,使用NaT.
If 'ignore', 无效的转换,将使用输入的数据.
#ParserError: year 120211204 is out of range: 120211204
pd.to_datetime(['120211204','20210101'])
# 无效的转换,将使用输入的数据
pd.to_datetime(['120211204','2021.02.01'], errors="ignore")
Index(['120211204', '2021.02.01'], dtype='object')
# 无效的转换,使用NaT
pd.to_datetime(['120211204','2021.02.01'], errors="coerce")
DatetimeIndex(['NaT', '2021-02-01'], dtype='datetime64[ns]',
freq=None)
# 自动识别
pd.to_datetime(pd.Series(["Jul 31, 2018", "2018.05.10", None]))
0 2018-07-31
1 2018-05-10
2 NaT
dtype: datetime64[ns]
timedelta类
timedelta 是 Python 标准库 datetime 模块中的一个类,用于表示两个日期或时间之间的差异,即时间间隔。这个类非常有用,因为它可以帮助你进行日期和时间的计算,比如添加或减去一段时间。
timedelta 的构造
timedelta 对象可以表示几天、几小时、几分钟、几秒甚至微秒的差异。创建一个 timedelta 对象时,可以使用以下参数:
days:天数seconds:秒数microseconds:微秒数milliseconds:毫秒数minutes:分钟数hours:小时数weeks:周数
所有这些参数都是可选的,可以根据需要组合使用。
基本用法示例
下面是一些使用 timedelta 的基本示例:
1. 创建 timedelta 对象
from datetime import timedelta
# 创建一个 timedelta 对象,表示 1 天 2 小时 30 分钟
delta = timedelta(days=1, hours=2, minutes=30)
print(delta)2. 日期和时间计算
from datetime import datetime
# 当前日期和时间
now = datetime.now()
# 使用 timedelta 添加时间
future = now + timedelta(days=10) # 当前时间后 10 天
print(future)
# 使用 timedelta 减去时间
past = now - timedelta(weeks=3) # 当前时间前 3 周
print(past)3. 时间差的属性
timedelta 对象有几个属性,如 days, seconds, 和 microseconds,通过它们可以访问时间差的具体部分。
delta = timedelta(days=15, hours=5, minutes=30)
print("Days:", delta.days)
print("Seconds:", delta.seconds) # 注意这里的秒数是小时和分钟转换成的秒数
print("Microseconds:", delta.microseconds)4. 总秒数
如果你想获取 timedelta 对象总共包含的秒数,可以使用 total_seconds() 方法。
delta = timedelta(days=1, hours=2, minutes=30)
print("Total seconds:", delta.total_seconds())Pandas读取文件
read_csv() 用于读取文本文件
read_excel() 用于读取文本文件
read_json() 用于读取 json 文件
read_sql_query() 读取 sql 语句的,
CSV文件读取
read_csv(filepath_or_buffer, sep=',', header='infer', names=None,
index_col=None, usecols=None, squeeze=None, prefix=None,
mangle_dupe_cols=True, dtype=None, engine=None, converters=None,
true_values=None, false_values=None, skipinitialspace=False,
skiprows=None, skipfooter=0, nrows=None, na_values=None,
keep_default_na=True, na_filter=True, verbose=False,
skip_blank_lines=True, parse_dates=None,
infer_datetime_format=False, keep_date_col=False, date_parser=None,
dayfirst=False, cache_dates=True, iterator=False, chunksize=None,
compression='infer', thousands=None, decimal='.',
lineterminator=None, quotechar='"', quoting=0, doublequote=True,
escapechar=None, comment=None, encoding=None,
encoding_errors='strict', dialect=None, error_bad_lines=None,warn_bad_lines=None, on_bad_lines=None, delim_whitespace=False,
low_memory=True, memory_map=False, float_precision=None,
storage_options=None)
基本参数
1、filepath_or_buffer:数据输入的路径:可以是文件路径、可以是URL,也可以是
实现read方法的任意对象。这个参数,就是我们输入的第一个参数。
import pandas as pd
pd.read_csv(r"data\students.csv")
2、sep:读取csv文件时指定的分隔符,默认为逗号。注意:"csv文件的分隔符" 和 "我们读取
csv文件时指定的分隔符" 一定要一致。
缺失值的处理
缺失值的判断
isnull():判断具体的某个值是否是缺失值,如果是则返回True,反之则为False
删除缺失值
df.dropna(axis=0, how='any', thresh=None, subset=None,
inplace=False)
axis:{0或'index',1或'columns'},默认为0 确定是否删除了包含缺少值的行或列
*0或“索引”:删除包含缺少值的行。
*1或“列”:删除包含缺少值的列。
how:{'any','all'},默认为'any' 确定是否从DataFrame中删除行或列,至少一个NA或所有NA
*“any”:如果存在任何NA值,请删除该行或列。
*“all”:如果所有值都是NA,则删除该行或列。
thresh: int 需要至少非NA值数据个数
subset: 定义在哪些列中查找缺少的值
inplace:是否更改源数据
缺失值补充
一般有用0填充,
用平均值填充,
用众数填充(大多数时候用这个),众数是指一组数据中出现次数最多的那个数据,一组数
据可以有多个众数,也可以没有众数
向前填充(用缺失值的上一行对应字段的值填充,比如D3单元格缺失,那么就用D2单元格的值
填充)、
向后填充(与向前填充对应)等方式。
df.fillna(
value=None,
method=None,
axis=None,
inplace=False,
limit=None,
downcast=None,
)
- value: 用于填充的值(例如0),或者是一个dict/Series/DataFrame值,指定每个索引(对于一个系列)或列(对于一个数据帧)使用哪个值。不在dict/Series/DataFram中的值将不会被填充。此值不能是列表。
- method:ffill-->将上一个有效观察值向前传播 bfill-->将下一个有效观察值向后传播
- axis:用于填充缺失值的轴。
- inplace:是否操作源数据
- limit:要向前/向后填充的最大连续NaN值数
# 将所有NaN元素替换为0
df.fillna(0)
# 我们还可以向前或向后传播非空值
df.fillna(method="ffill") # 将列“A”、“B”、“C”和“D”中的所有NaN元素分别替换为0、1、2和3。
values = {"A": 0, "B": 1, "C": 2, "D": 3}
df.fillna(value=values)
数据查询
按数值,列表,区间,条件,函数五种方法
查询数据的几种方法
1、df.loc方法,根据行列的标签值查询
2、df.iloc方法,根据行列的数字位置查询
3、df.where 方法
4、df.query方法
.loc既能查询,又能覆盖写入
使用df.loc查询数据的方法
1、使用单个label值进行查询
2、使用值列表批量查询
3、使用数值区间进行范围查询
4、使用条件表达式查询
5、调用函数查询
第零步
1、读取数据
2、df.set_index('ymd',inplace=True) # 设定索引为日期,方便按日期筛选
3、替换掉温度的后缀C
df.loc[:,"bwendu"] = df["bwendu"].str.replace("C","").astype("int32")
第一步 使用单个label值进行查询
1 、# 得到单个值
df.loc[ ‘2018-01-03’,‘bWendu’] # 2
2、#得到一个Series
df.loc ['2018-01-03’,['bWendu', ’ywendu’]]
第二步 使用值列表批量查询
1、#得到Series
df.loc[[’2018-01-03’,’2018-01-04’,’2018-01-05’],’bwendu’]
2、#得到DataFrame
df.loc[[ 2018-01-03',’2018-01-04',’2018-01-05’],['bwendu', ’ywendu’]]
第三步 使用数值区间进行范围查询
1、#行index按区间
df.loc[ ’2018-01-03’: '2018-01-05’,’bwendu’]
2、#列index按区间
df.loc[' 2018-01-03’,’bwendu’: 'fengxiang’]
3、#行和列都按区间查询
df.loc[ '2018-01-03’:'2018-01-05',’bWendu’: 'fengxiang']
第四步 使用条件表达式查询
df. loc[df["yWendu”]<-10,:]
第五步 调用函数查询
1、#直接号lambda表达式
df.loc[lambda df :(dfl"bwendu"]<=30)&(df["yWendu"]>=15),:]
新增数据列
直接赋值,apply,assign、分条件赋值
第零步 读取数据
1、 直接赋值
实例:清理温度列,变成数字类型
# 替换掉温度的后缀℃
df.loc[:,"bWendu"]=df["bWendu"].str.replace("℃","").astype('int32’)
df.loc[:,"yWendu"]=df["yWendu".str.replace("℃”,"").astype('int32’)
新增一列
# 注意,df[“bendu"]其实是一个Series,后面的减法返回的是Seriesdf.
loc[:,"wencha"]= df["bWendu"]- df["yWendu"]
2、df.apply方法
def get_wendu_type(x):
if x["bWendu"]> 33:
return "高温"
if x["yWendu"]< -10:
return"低温"
return "常温"
#注意需要设置axis==1,这是series的index是columns
df. loc[:,"wendu_type"]= df.apply(get_wendu _type, axis=1)
# 查看温度类型的计数
df["wendu_type"].value_counts()
3、df.assign方法
import pandas as pd
import numpy as np在数据分析中,经常会遇到这样的情况:
根据某一列(或多列)标签把数据划分为不同的组别,然后再对其进行数据分析。
比如,某网站对注册用户的性别或者年龄等进行分组,从而研究出网站用户的画像(特点)。在 Pandas 中,要完成数据的分组操作,需要使用 groupby() 函数,它和 SQL 的GROUP BY操作非常相似。
在划分出来的组(group)上应用一些统计函数,从而达到数据分析的目的,比如对分组数据进行聚合、转换,或者过滤。这个过程主要包含以下三步:
- 拆分(Spliting):表示对数据进行分组;
- 应用(Applying):对分组数据应用聚合函数,进行相应计算;
- 合并(Combining):最后汇总计算结果。
模拟生成的10个样本数据,代码和数据如下:
company=["A","B","C"]
data=pd.DataFrame({
"company":[company[x] for x in np.random.randint(0,len(company),10)],
"salary":np.random.randint(5,50,10),
"age":np.random.randint(15,50,10)
}
)
data| company | salary | age | |
|---|---|---|---|
| 0 | A | 14 | 38 |
| 1 | C | 9 | 25 |
| 2 | C | 33 | 48 |
| 3 | B | 26 | 29 |
| 4 | B | 44 | 49 |
| 5 | B | 8 | 43 |
| 6 | C | 10 | 26 |
| 7 | A | 30 | 33 |
| 8 | A | 13 | 22 |
| 9 | B | 20 | 35 |
一、Groupby的基本原理
在pandas中,实现分组操作的代码很简单,仅需一行代码,在这里,将上面的数据集按照company字段进行划分:
group = data.groupby("company")
group<pandas.core.groupby.generic.DataFrameGroupBy object at 0x00000227B389AD30>
将上述代码输入ipython后,会得到一个DataFrameGroupBy对象
那这个生成的DataFrameGroupBy是啥呢?
对data进行了groupby后发生了什么?
ipython所返回的结果是其内存地址,并不利于直观地理解,为了看看group内部究竟是什么,这里把group转换成list的形式来看一看:
list(group)[('A',
company salary age
0 A 32 18
1 A 30 29
6 A 44 26
7 A 6 34
9 A 37 33),
('B',
company salary age
2 B 34 38
4 B 30 31
8 B 48 18),
('C',
company salary age
3 C 44 37
5 C 28 19)]
转换成列表的形式后,可以看到,列表由三个元组组成,每个元组中,
第一个元素是组别(这里是按照company进行分组,所以最后分为了A,B,C),
第二个元素的是对应组别下的DataFrame,整个过程可以图解如下:

总结来说,groupby的过程就是将原有的DataFrame按照groupby的字段(这里是company),划分为若干个分组DataFrame,被分为多少个组就有多少个分组DataFrame。所以说,在groupby之后的一系列操作(如agg、apply等),均是基于子DataFrame的操作。
理解了这点,也就基本摸清了Pandas中groupby操作的主要原理。下面来讲讲groupby之后的常见操作
二、agg 聚合操作
聚合(Aggregation)操作是groupby后非常常见的操作,会写SQL的朋友对此应该是非常熟悉了。聚合操作可以用来求和、均值、最大值、最小值等,下面的表格列出了Pandas中常见的聚合操作。
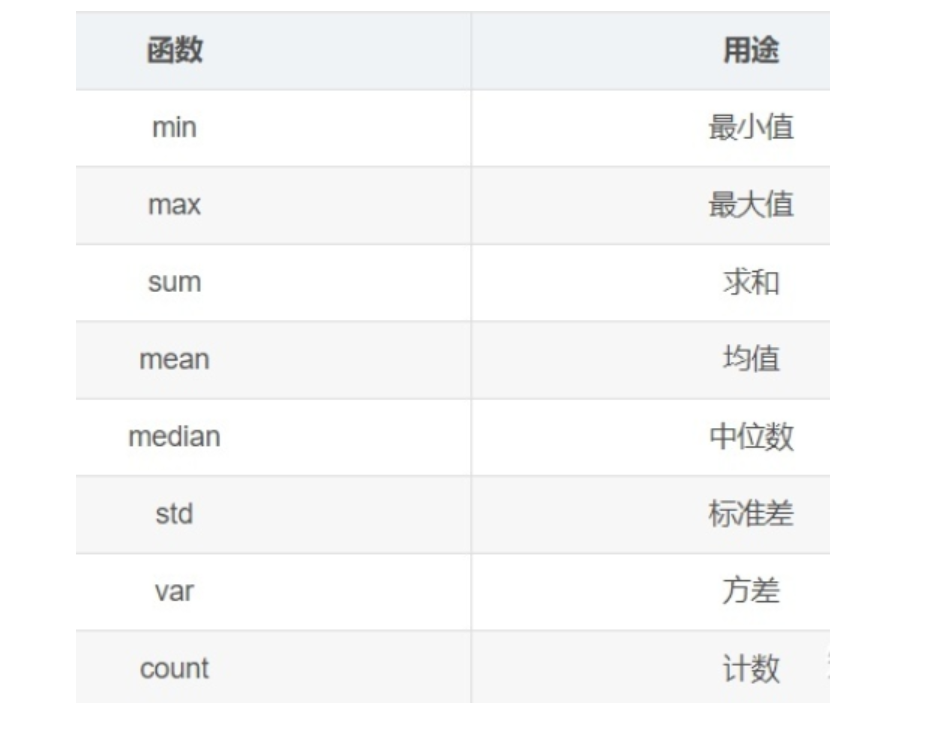
针对样例数据集,如果我想求不同公司员工的平均年龄和平均薪水,可以按照下方的代码进行:
data.groupby("company").agg('mean')如果想对针对不同的列求不同的值,比如要计算不同公司员工的平均年龄以及薪水的中位数,可以利用字典进行聚合操作的指定:
data.groupby('company').agg({'salary':'median','age':'mean'})
三、transform 转换值
transform是一种什么数据操作?
和agg有什么区别呢?
为了更好地理解transform和agg的不同,下面从实际的应用场景出发进行对比。
在上面的agg中,我们学会了如何求不同公司员工的平均薪水,
如果现在需要在原数据集中新增一列avg_salary,代表员工所在的公司的平均薪水(相同公司的员工具有一样的平均薪水),该怎么实现呢?
如果按照正常的步骤来计算,需要先求得不同公司的平均薪水,然后按照员工和公司的对应关系填充到对应的位置,不用transform的话
# to_dict将表格中的数据转换成字典格式
avg_salary_dict= data.groupby('company')['salary'].mean().to_dict()
avg_salary_dict{'A': 19.0, 'B': 24.5, 'C': 17.333333333333332}
# map()函数可以用于Series对象或DataFrame对象的一列,接收函数作为或字典对象作为参数,返回经过函数或字典映射处理后的值。
data['avg_salary'] = data['company'].map(avg_salary_dict)
data| company | salary | age | avg_salary | |
|---|---|---|---|---|
| 0 | A | 32 | 18 | 29.800000 |
| 1 | A | 30 | 29 | 29.800000 |
| 2 | B | 34 | 38 | 37.333333 |
| 3 | C | 44 | 37 | 36.000000 |
| 4 | B | 30 | 31 | 37.333333 |
| 5 | C | 28 | 19 | 36.000000 |
| 6 | A | 44 | 26 | 29.800000 |
| 7 | A | 6 | 34 | 29.800000 |
| 8 | B | 48 | 18 | 37.333333 |
| 9 | A | 37 | 33 | 29.800000 |
如果使用transform的话,仅需要一行代码:
data['avg_salary1'] = data.groupby('company')['salary'].transform('mean')
data还是以图解的方式来看看进行groupby后transform的实现过程(为了更直观展示,图中加入了company列,实际按照上面的代码只有salary列):

图中的大方框是transform和agg所不一样的地方,对agg而言,会计算得到A,B,C公司对应的均值并直接返回,
但对transform而言,则会对每一条数据求得相应的结果,同一组内的样本会有相同的值,
组内求完均值后会按照原索引的顺序返回结果,如果有不理解的可以拿这张图和agg那张对比一下。
四、apply
它相比agg和transform而言更加灵活,能够传入任意自定义的函数,实现复杂的数据操作
对于groupby后的apply,以分组后的子DataFrame作为参数传入指定函数的,基本操作单位是DataFrame
假设我现在需要获取各个公司年龄最大的员工的数据,该怎么实现呢?可以用以下代码实现:
def get_oldest_staff(x):
# 输入的数据按照age字段进行排序
df = x.sort_values(by = 'age',ascending=True)
# 返回最后一条数据
return df.iloc[-1,:]
oldest_staff = data.groupby('company',as_index=False).apply(get_oldest_staff)
oldest_staff这样便得到了每个公司年龄最大的员工的数据,整个流程图解如下: 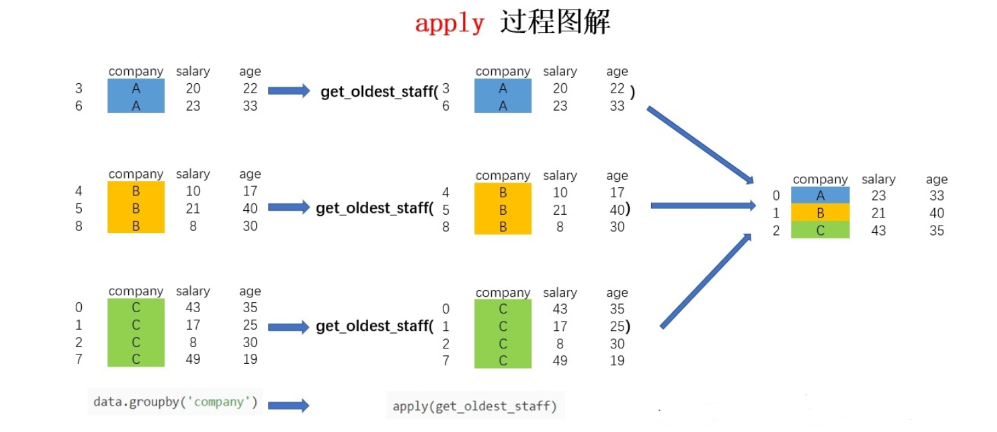
虽然说apply拥有更大的灵活性,但apply的运行效率会比agg和transform更慢。所以,groupby之后能用agg和transform解决的问题还是优先使用这两个方法,实在解决不了了才考虑使用apply进行操作
Pandas读取文件
read_csv() 用于读取文本文件
read_excel() 用于读取文本文件
read_json() 用于读取 json 文件
read_sql_query() 读取 sql 语句的CSV文件读取
方法详细说明:
read_csv(filepath_or_buffer, sep=',', header='infer', names=None, index_col=None, usecols=None, squeeze=None, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, skipfooter=0, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=None, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, cache_dates=True, iterator=False, chunksize=None, compression='infer', thousands=None, decimal='.', lineterminator=None, quotechar='"', quoting=0, doublequote=True, escapechar=None, comment=None, encoding=None, encoding_errors='strict', dialect=None, error_bad_lines=None, warn_bad_lines=None, on_bad_lines=None, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None, storage_options=None)基本参数
1、filepath_or_buffer:数据输入的路径:可以是文件路径、可以是URL,也可以是实现read方法的任意对象。这个参数,就是我们输入的第一个参数。
import pandas as pd
pd.read_csv(r"data\students.csv")
# 还可以是一个URL,如果访问该URL会返回一个文件的话,那么pandas的read_csv函数会自动将
# 该文件进行读取。比如:我们服务器上放的数据,将刚才的文件返回。
pd.read_csv("http://my-teaching.top/static/data/students.csv") # 需要网络请求,因此读取文件比较慢
# 里面还可以是一个 _io.TextIOWrapper,比如:
f = open(r"data\students.csv", encoding="utf-8")
pd.read_csv(f)
# pandas默认使用utf-8读取文件2、sep:读取csv文件时指定的分隔符,默认为逗号。注意:"csv文件的分隔符" 和 "我们读取csv文件时指定的分隔符" 一定要一致。
df = pd.read_csv(r"data\students_step.csv", sep="|")3.delim_whitespace :默认为 False,设置为 True 时,表示分割符为空白字符,可以是空格、"\t"等等。不管分隔符是什么,只要是空白字符,那么可以通过delim_whitespace=True进行读取。
df = pd.read_csv(r"data\students_whitespace.txt", sep=" ")
df
等于
df = pd.read_csv(r"data\students_whitespace.txt", delim_whitespace=True)
df4.header 和names
header 参数:
作用:
header参数用于指定应将哪一行作为列名。默认情况下,Pandas 会将第一行数据作为列名,如果数据中不包含列名,则列名默认为整数索引。使用
参数可以接受不同的值:
- 如果将
header=None,表示数据中不包含列名,Pandas 会自动为每一列生成整数索引作为列名。 - 如果将
header=0,表示将第一行数据作为列名。 - 如果将
header=n(其中 n 是整数),表示将第 n 行数据作为列名。 - 如果将
header设置为一个列表,例如header=[0, 1],表示将第 0 行和第 1 行数据合并作为列名。
names 参数:
- 作用:
names参数用于指定列名,通常在数据中不包含列名时使用。它允许用户手动指定列名。 - 使用:
names参数接受一个列表,列表中的每个元素都是一个字符串,表示对应列的名称。
- 如果将
pd.read_csv(r"data\students.csv",
names=["编号", "姓名", "地址", "性别", "出生日期"],
header=0)所以names和header的使用场景主要如下:
①. csv文件有表头并且是第一行,那么names和header都无需指定;
②. csv文件有表头、但表头不是第一行,可能从下面几行开始才是真正的表头和数据,这个时候指定header即可;
③. csv文件没有表头,全部是纯数据,那么我们可以通过names手动生成表头;
④. csv文件有表头、但是这个表头你不想用,这个时候同时指定names和header。先用header选出表头和数据,然后再用names将表头替换掉,就等价于将数据读取进来之后再对列名进行rename;4 index_col:我们在读取文件之后所得到的DataFrame的索引默认是0、1、2……,我们可以通过set_index设定索引,但是也可以在读取的时候就指定某列为索引。
df = pd.read_csv(r"data\students.csv", index_col="birthday")
df.index=df['birthday']
del df['birthday']
df
df2 = pd.read_csv(r"data\students.csv", index_col=["gender","birthday"])
df2通用解析参数
- encoding:这只编码格式 utf-8 gbk
pd.read_csv(r"data\students_gbk.csv", encoding="gbk")- dtype:在读取数据的时候,设定字段的类型。比如,公司员工的id一般是:00001234,如果默认读取的时候,会显示为1234,所以这个时候要把他转为字符串类型,才能正常显示为00001234:
df = pd.read_csv(r"data\students_step_001.csv", sep="|", dtype ={"id":str})- converters:在读取数据的时候对列数据进行变换,例如将id增加10,但是注意 int(x),在使用converters参数时,解析器默认所有列的类型为 str,所以需要进行类型转换。
pd.read_csv('data\students.csv', converters={"id": lambda x: int(x) + 10})4.pandas解析数据时用的引擎,目前解析引擎有两种:c、python。默认为 c,因为 c 引擎解析速度更快,但是特性没有 python 引擎全
pd.read_csv('data\students.csv', skipfooter=1, engine="python", encoding="utf-8")空值处理相关参数
na_values:该参数可以配置哪些值需要处理成 NaN
将字段为女或者朱梦雪的设置为NaN
pd.read_csv('data\students.csv', na_values=["女", "朱梦雪"])时间处理相关参数
1、parse_dates:指定某些列为时间类型,这个参数一般搭配date_parser使用。
2、date_parser:是用来配合parse_dates参数的,因为有的列虽然是日期,但没办法直接转化,需要我们指定一个解析格式:
df = pd.read_csv('data\students.csv')
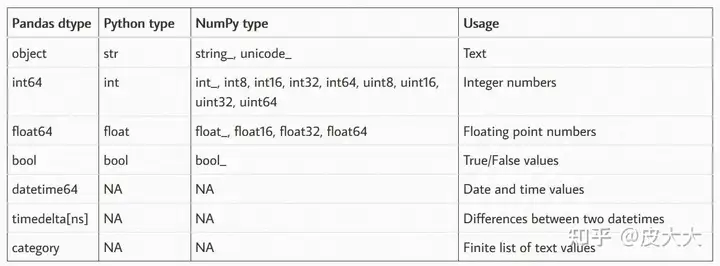
dfdf.dtypesid int64
name object
address object
gender object
birthday object
dtype: object
df = pd.read_csv('data\students.csv', parse_dates=["birthday"])
dfdf.dtypesdf2 = pd.read_csv('data\students_年月日.csv', parse_dates=["birthday"])
print(df2)
df2.dtypes id name address gender birthday
0 1 朱梦雪 地球村 女 2004年11月2日
1 2 许文博 月亮星 女 2003年8月7日
2 3 张兆媛 艾尔星 女 2004年11月2日
3 4 付延旭 克哈星 男 2003年10月11日
4 5 王杰 查尔星 男 2002年6月12日
5 6 董泽宇 塔桑尼斯 男 2002年2月12日
id int64
name object
address object
gender object
birthday object
dtype: object
import pandas as pd
from datetime import datetime
df2 = pd.read_csv('data\students_年月日.csv',
parse_dates=["birthday"],
date_parser=lambda x: datetime.strptime(x, "%Y年%m月%d日"))
print(df2)
df2.dtypes id name address gender birthday
0 1 朱梦雪 地球村 女 2004-11-02
1 2 许文博 月亮星 女 2003-08-07
2 3 张兆媛 艾尔星 女 2004-11-02
3 4 付延旭 克哈星 男 2003-10-11
4 5 王杰 查尔星 男 2002-06-12
5 6 董泽宇 塔桑尼斯 男 2002-02-12
id int64
name object
address object
gender object
birthday datetime64[ns]
dtype: object
当我们遇到一个超级大的DataFrame,里面有一列类型为字符串,要将每一行的字符串都用同一方式进行处理, 一般会想到遍历整合DataFrame,但是如果直接这样做的话将会耗费很长时间,有时几个小时都处理不完。 因此我们将学习pandas快速处理字符串方法。
str方法的简介
Python会处理字符串起来会很容易,作为工具包的Pandas同样可以简单快速的处理字符串, 几乎把Python内置的字符串方法都给复制过来了,这种方法就是Pandas内置的str方法, 通俗来说就可以将series和index对象中包含字符串的部分简单看作单个字符串处理,达到批量简单快速处理的目的
lower()将的字符串转换为小写。upper()将的字符串转换为大写。len()得出字符串的长度。strip()去除字符串两边的空格(包含换行符)。split()用指定的分割符分割字符串。cat(sep="")用给定的分隔符连接字符串元素。contains(pattern)如果子字符串包含在元素中,则为每个元素返回一个布尔值 True,否则为 False。replace(a,b)将值 a 替换为值 b。count(pattern)返回每个字符串元素出现的次数。startswith(pattern)如果 Series 中的元素以指定的字符串开头,则返回 True。endswith(pattern)如果 Series 中的元素以指定的字符串结尾,则返回 True。findall(pattern)以列表的形式返出现的字符串。find(pattern)返回字符串第一次出现的索引位置。
注意:上述所有字符串函数全部适用于 DataFrame 对象,同时也可以与 Python 内置的字符串函数一起使用,这些函数在处理 Series/DataFrame 对象的时候会自动忽略缺失值数据(NaN)
import pandas as pd
import numpy as nplower()将的字符串转换为小写。
s = pd.Series(['C', 'Python', 'java', 'go', np.nan, '1125','javascript'])
s.str.lower()0 c
1 python
2 java
3 go
4 NaN
5 1125
6 javascript
dtype: object
- upper() 将的字符串转换为大写。
s = pd.Series(['C', 'Python', 'java', 'go', np.nan, '1125','javascript'])
s.str.upper()0 C
1 PYTHON
2 JAVA
3 GO
4 NaN
5 1125
6 JAVASCRIPT
dtype: object
len()得出字符串的长度。
s = pd.Series(['C', 'Python', 'java', 'go', np.nan, '1125','javascript'])
s.str.len()0 1.0
1 6.0
2 4.0
3 2.0
4 NaN
5 4.0
6 10.0
dtype: float64
strip()去除字符串两边的空格(包含换行符)。
s = pd.Series(['C ', ' Python\t \n', ' java ', 'go\t', np.nan, '\t1125 ','\tjavascript'])
s_strip = s.str.strip(" ")
s_strip0 C
1 Python\t \n
2 java
3 go\t
4 NaN
5 \t1125
6 \tjavascript
dtype: object
print(s[1]) Python
s_strip[2]'java'
split()用指定的分割符分割字符串。
s = pd.Series(['Zhang hua',' Py thon\n',' java ','go','11 25 ','javascript'])
print(s.str.split(" "))0 [Zhang, hua]
1 [, Py, thon\n]
2 [, , , java, , , ]
3 [go]
4 [11, 25, ]
5 [javascript]
dtype: object
# 不带参数,会先执行strip(),再默认以空格分割
print(s.str.split())0 [Zhang, hua]
1 [Py, thon]
2 [java]
3 [go]
4 [11, 25]
5 [javascript]
dtype: object
print(s.str.strip().str.split(" "))0 [Zhang, hua]
1 [Py, thon]
2 [java]
3 [go]
4 [11, 25]
5 [javascript]
dtype: object
cat(sep="")用给定的分隔符连接字符串元素。
s = pd.Series(['C', 'Python', 'java', 'go', np.nan, '1125','javascript'])
#会自动忽略NaN
s_cat = s.str.cat(sep="_")
s_cat'C_Python_java_go_1125_javascript'
s_cat.split("_")['C', 'Python', 'java', 'go', '1125', 'javascript']
pd.Series(s_cat.split("_"))0 C
1 Python
2 java
3 go
4 1125
5 javascript
dtype: object
contains(pattern)如果子字符串包含在元素中,则为每个元素返回一个布尔值 True,否则为 False。
s = pd.Series(['C ',' Python','java','go','1125 ','javascript'])
s.str.contains(" ")
# 取出s中包含空格的元素0 True
1 True
2 False
3 False
4 True
5 False
dtype: bool
s[s.str.contains(" ")]0 C
1 Python
4 1125
dtype: object
replace(a,b)将值 a 替换为值 b。
s = pd.Series(['C ',' Python','java','go','1125 ','javascript'])
s.str.replace("java","python")0 C
1 Python
2 python
3 go
4 1125
5 pythonscript
dtype: object
count(pattern)返回每个字符串元素出现的次数。
s = pd.Series(['C ','Python Python','Python','go','1125 ','javascript'])
s.str.count("Python")0 0
1 2
2 1
3 0
4 0
5 0
dtype: int64
startswith(pattern)如果 Series 中的元素以指定的字符串开头,则返回 True。endswith(pattern)如果 Series 中的元素以指定的字符串结尾,则返回 True。
s = pd.Series(['C ',' Python','java','go','1125 ','javascript'])
#若以指定的"j"开头则返回True
print(s.str.startswith("j"))0 False
1 False
2 True
3 False
4 False
5 True
dtype: bool
#若以指定的"j"开头则返回True
print(s.str.endswith("a"))0 False
1 False
2 True
3 False
4 False
5 False
dtype: bool
repeat(value)以指定的次数重复每个元素。
s = pd.Series(['C ',' Python','java','go','1125 ','javascript'])
print(s.str.repeat(3))0 C C C
1 Python Python Python
2 javajavajava
3 gogogo
4 1125 1125 1125
5 javascriptjavascriptjavascript
dtype: object
find(pattern)返回字符串第一次出现的索引位置。
s = pd.Series(['C ',' Python','java','go','1125 ','javascript'])
print(s.str.find("a"))
# 如果返回 -1 表示该字符串中没有出现指定的字符。0 -1
1 -1
2 1
3 -1
4 -1
5 1
dtype: int64
findall(pattern)以列表的形式返出现的字符串。
s = pd.Series(['C ',' Python','java','go','1125 ','javascript'])
print(s.str.findall("a"))0 []
1 []
2 [a, a]
3 []
4 []
5 [a, a]
dtype: object
深入浅出Pandas 数据分析V1.1
- 一切从爆炸函数开始
- Series类型数据
- 创建DataFrame:10种方式任你选
- 各种骚气的Pandas取数
- 五花八门的Pandas取数
- 最后一篇:玩转Pandas取数
- 数据处理的基石:数据探索
- Pandas数据类型操作
- 图解Pandas的groupby机制
- 图解Pandas的排名rank机制
- 图解Pandas的排序sort_values
- 图解Pandas缺失值、空值处理
- 图解Pandas重复值处理
- 图解Pandas数据合并merge
- 图解Pandas数据合并concat/join/append
- 图解Pandas轴旋转函数:stack和unstack
- 图解Pandas透视表、交叉表
- Pandas的3个宝藏函数:map、apply、applymap
pd.to_numeric函数简介
pd.to_numeric函数主要用于将一个或一组值转换为数值类型。其基本语法如下:
pandas.to_numeric(arg, errors='raise', downcast=None)- arg:需要转换的对象,可以是单个数值、列表、Series等。
- errors:控制非数值的处理方式,默认为’raise’,即抛出异常;其他选项包括’coerce’(将非数值强制转为NaN)和’ignore’(保持原值)。
- downcast:指定转换的数值类型,可以是’integer’、‘signed’、‘unsigned’、'float’等。
boxplot
plt.boxplot() 函数可以接受多种类型的数据。以下是它可以接受的数据类型:
列表 (List): 你可以传递一个包含数值的列表。
data = [1, 2, 3, 4, 5] plt.boxplot(data)包含列表的列表 (List of Lists): 你可以传递一个包含多个列表的列表,每个列表代表一组数据。
data = [[1, 2, 3, 4, 5], [2, 3, 4, 5, 6], [3, 4, 5, 6, 7]] plt.boxplot(data)NumPy 数组 (NumPy Arrays): 你可以传递一个 NumPy 数组,或一个包含多个 NumPy 数组的数组。
import numpy as np data = np.array([1, 2, 3, 4, 5]) plt.boxplot(data) data = [np.array([1, 2, 3, 4, 5]), np.array([2, 3, 4, 5, 6])] plt.boxplot(data)pandas Series: 你可以传递一个
pandas.Series对象,或一个包含多个pandas.Series对象的列表。import pandas as pd data = pd.Series([1, 2, 3, 4, 5]) plt.boxplot(data) data = [pd.Series([1, 2, 3, 4, 5]), pd.Series([2, 3, 4, 5, 6])] plt.boxplot(data)包含数值的字典 (Dictionary of Lists/Arrays/Series): 你可以传递一个字典,其中键是标签,值是列表、NumPy 数组或
pandas.Series对象。data = { 'Group 1': [1, 2, 3, 4, 5], 'Group 2': [2, 3, 4, 5, 6], 'Group 3': [3, 4, 5, 6, 7] } plt.boxplot(data.values(), labels=data.keys())
以下是一个使用多个 pandas.Series 的例子:
import matplotlib.pyplot as plt
import pandas as pd
# 创建示例数据
data1 = pd.Series([1, 2, 3, 4, 5])
data2 = pd.Series([2, 3, 4, 5, 6])
data3 = pd.Series([3, 4, 5, 6, 7])
# 将数据放入列表
data = [data1, data2, data3]
# 设置标签
labels = ['Group 1', 'Group 2', 'Group 3']
# 绘制箱线图
plt.boxplot(data, labels=labels)
plt.ylabel('Values')
plt.title('Boxplot of Multiple Groups')
plt.show()通过这些方式,你可以使用 plt.boxplot() 函数绘制不同类型数据的箱线图。